Module openai

ballerinax/openai Ballerina library
Overview
OpenAI provides a suite of powerful AI models and services for natural language processing, code generation, image understanding, and more.
The ballerinax/openai package offers APIs to easily connect and interact with OpenAI's RESTful API endpoints, enabling seamless integration with models such as GPT, Whisper, and DALL·E.
Setup guide
To use the OpenAI connector, you must have access to the OpenAI API through an OpenAI account and API key.
If you do not have an OpenAI account, you can sign up for one here.
Step 1: Create/Open an OpenAI account
- Visit the OpenAI Platform.
- Sign in with your existing credentials, or create a new OpenAI account if you don’t already have one.
Step 2: Create a project
-
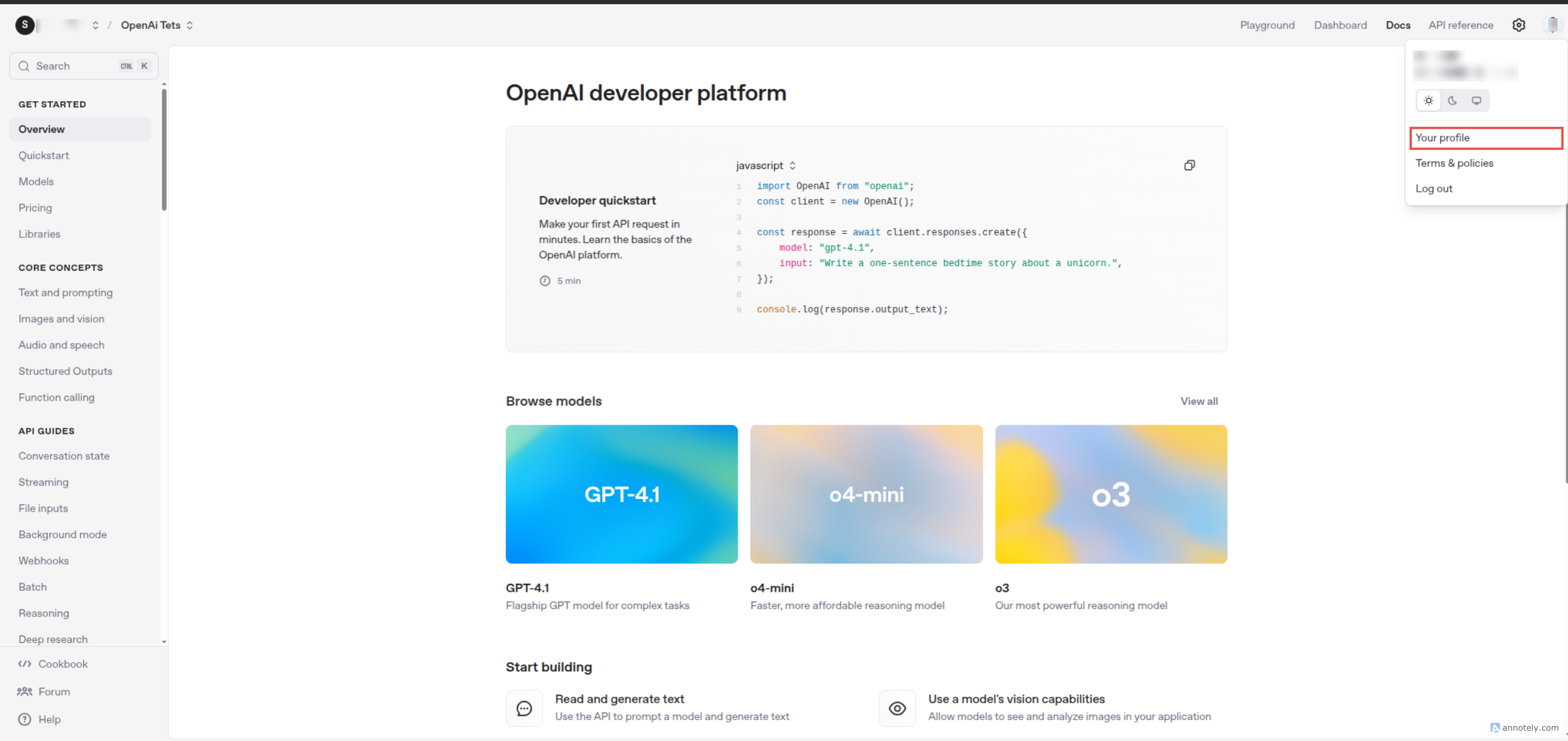
Once logged in, click on your profile icon in the top-right corner.
-
In the dropdown menu, click "Your Profile".
-
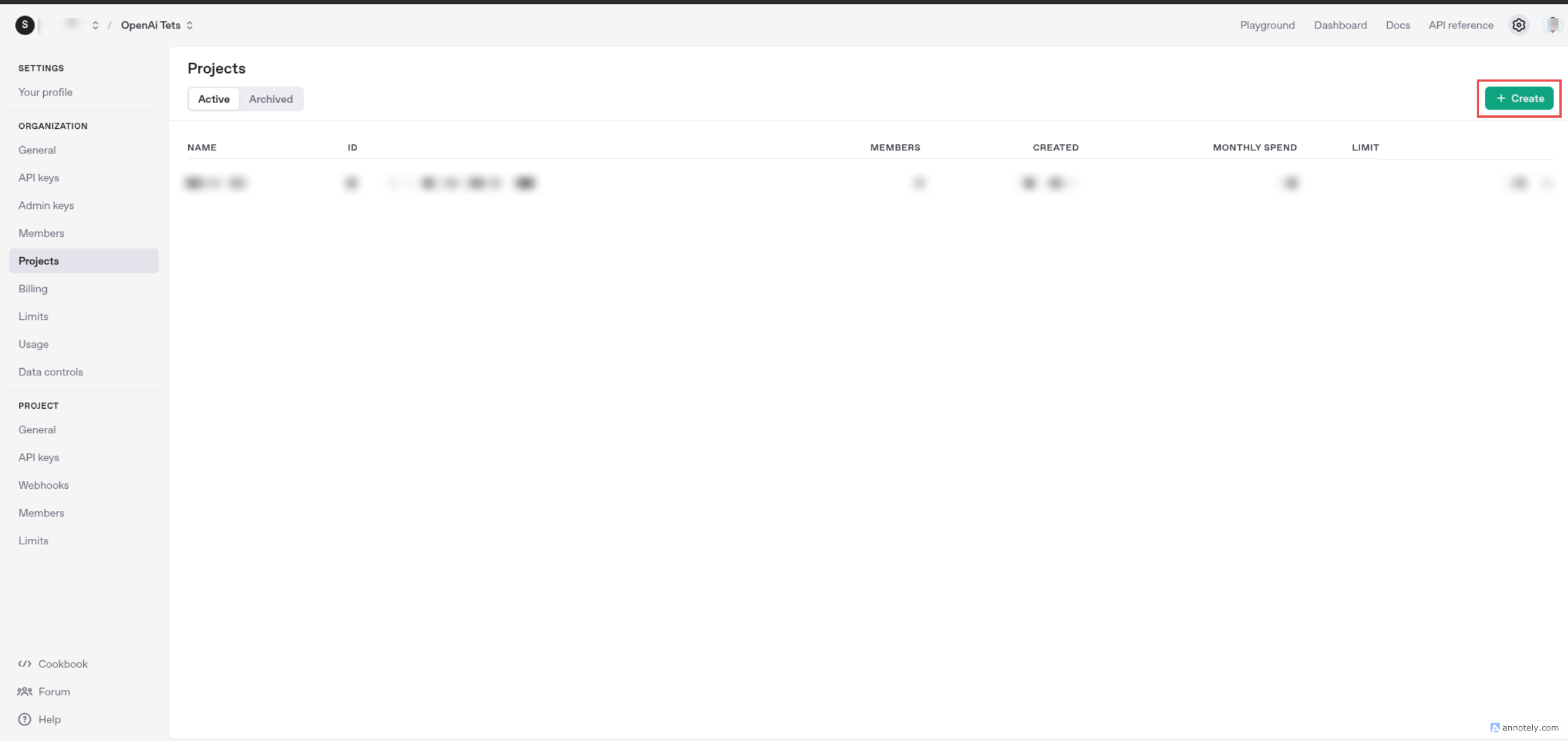
Then navigate to the "Projects" section from the sidebar to create a new project.
-
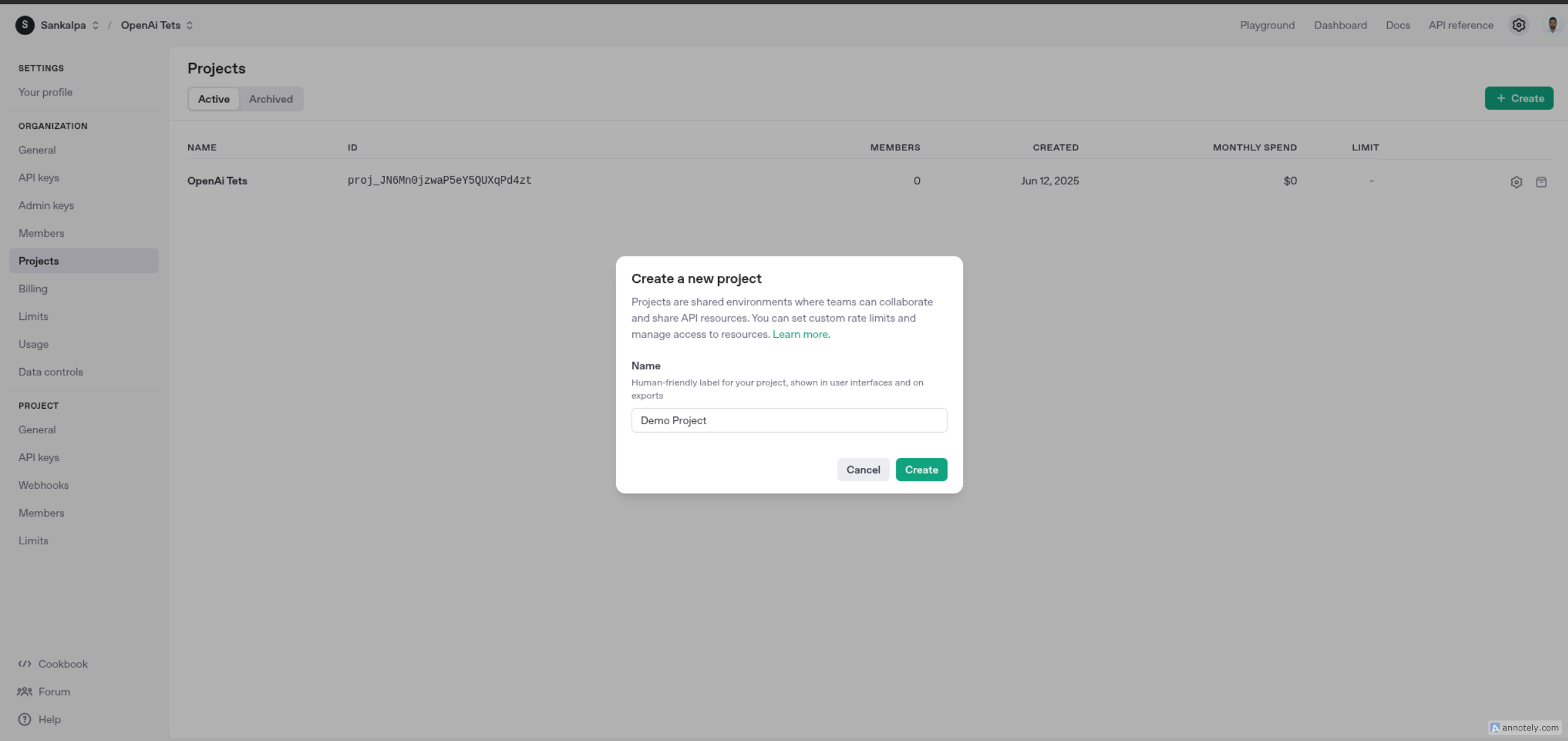
Click the "Create Project" button to create a new project.
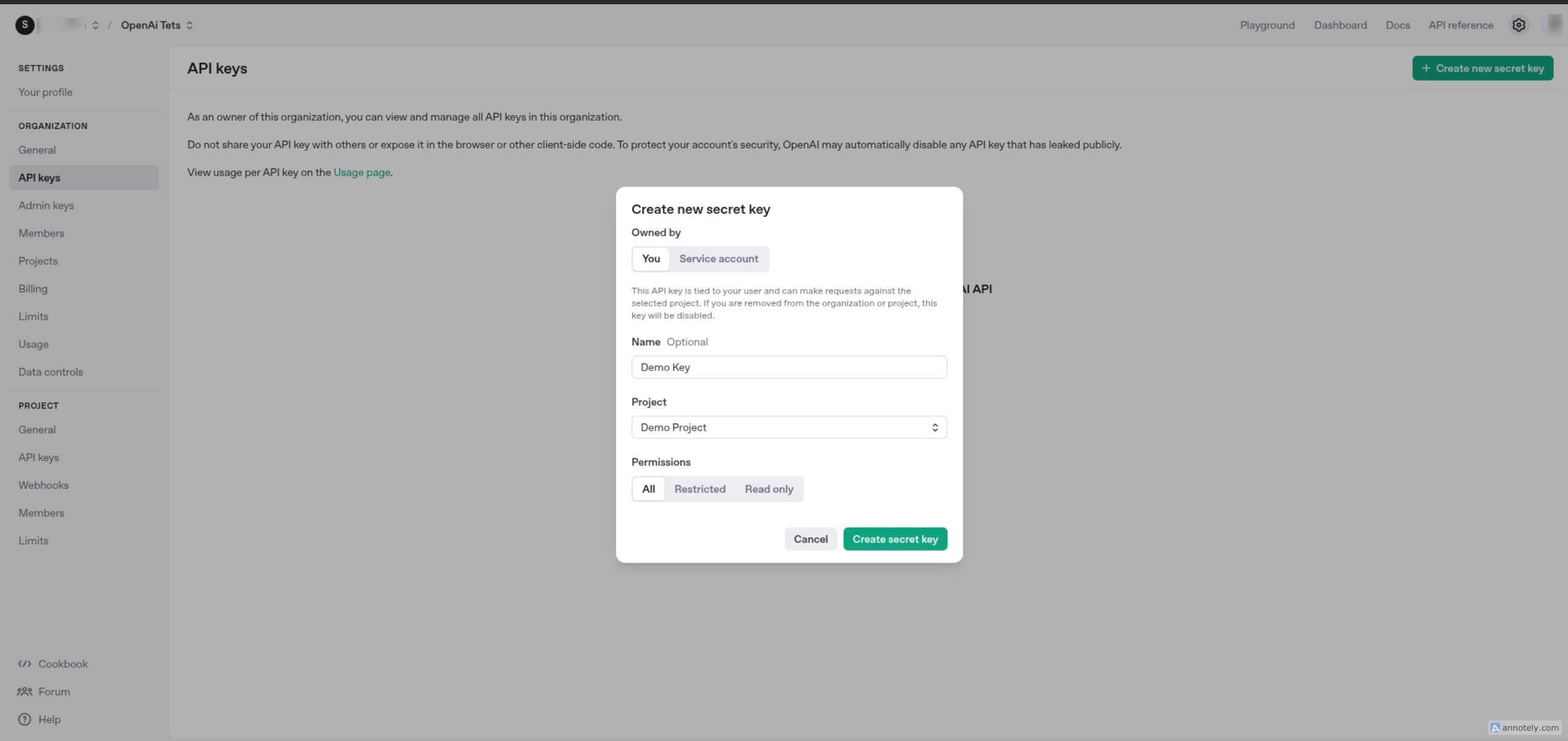
Step 3: Navigate to API Keys
-
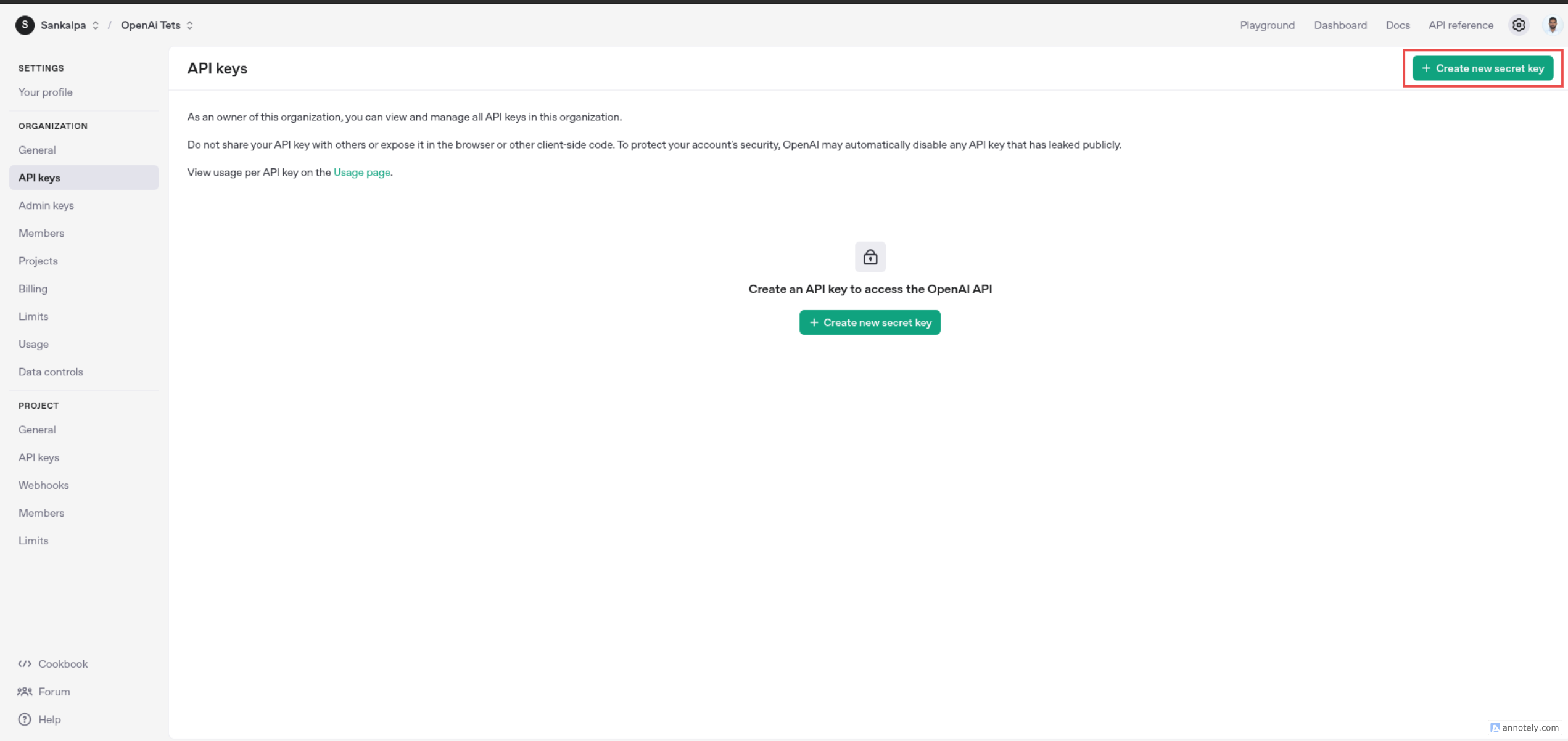
Navigate to the "API Keys" section from the sidebar and click the “+ Create new secret key” button. to create a new API Key.
-
Provide a name for the key (e.g., "Connector Key") and select Project name and then confirm.
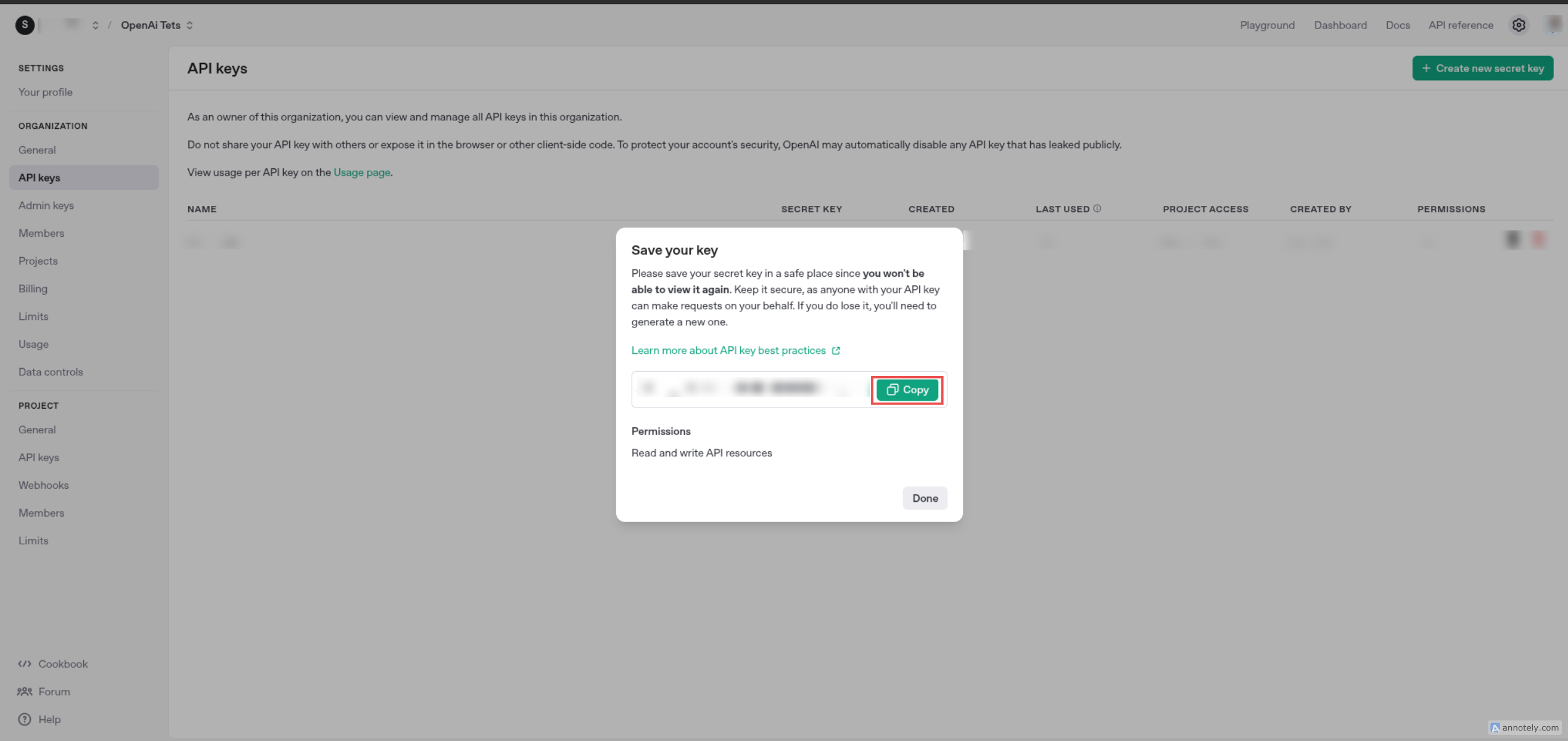
-
Copy the generated API key and store it securely. ( Note: You will not be able to view it again later.)
Quickstart
To use the OpenAI connector in your Ballerina application, update the .bal file as follows:
Step 1: Import the module
Import the openai module.
import ballerinax/openai;
Step 2: Instantiate a new connector
-
Create a
Config.tomlfile and, configure the obtained credentials in the above steps as follows:token = "<Access Token>" -
Create a
openai:ConnectionConfigwith the obtained access token and initialize the connector with it.configurable string token = ?; final openai:Client openai = check new({ auth: { token } });
Step 3: Invoke the connector operation
Now, utilize the available connector operations.
Create an Assistant
public function main() returns error? { openai:CreateAssistantRequest request = { model: "gpt-4o", name: "Math Tutor", description: null, instructions: "You are a personal math tutor.", tools: [{"type": "code_interpreter"}], toolResources: {"code_interpreter": {"file_ids": []}}, metadata: {}, topP: 1.0, temperature: 1.0, responseFormat: {"type": "text"} }; //Note: This header is required because the Assistants API is currently in beta, and OpenAI requires explicit opt-in. configurable map<string> headers = { "OpenAI-Beta": "assistants=v2" }; openai:AssistantObject response = check openai->/assistants.post(request, headers = headers); }
Step 4: Run the Ballerina application
bal run
Examples
The ballerinax/openai connector provides practical examples illustrating usage in various scenarios. Explore these examples, covering the following use cases:
- Financial Assistant - Build a Personal Finance Assistant that helps users manage their budget, track expenses, and get financial advice.
- Marketing Image Generator - Creates an assistant that takes a user’s description from the console, makes a DALL·E image with it.
Clients
openai: Client
The OpenAI REST API. Please see https://platform.openai.com/docs/api-reference for more details.
Constructor
Gets invoked to initialize the connector.
init (ConnectionConfig config, string serviceUrl)- config ConnectionConfig - The configurations to be used when initializing the
connector
- serviceUrl string "https://api.openai.com/v1" - URL of the target service
get assistants
function get assistants(map<string|string[]> headers, *ListAssistantsQueries queries) returns ListAssistantsResponse|errorReturns a list of assistants.
Parameters
- queries *ListAssistantsQueries - Queries to be sent with the request
Return Type
post assistants
function post assistants(CreateAssistantRequest payload, map<string|string[]> headers) returns AssistantObject|errorCreate an assistant with a model and instructions.
Parameters
- payload CreateAssistantRequest -
Return Type
- AssistantObject|error - OK
get assistants/[string assistantId]
function get assistants/[string assistantId](map<string|string[]> headers) returns AssistantObject|errorRetrieves an assistant.
Return Type
- AssistantObject|error - OK
post assistants/[string assistantId]
function post assistants/[string assistantId](ModifyAssistantRequest payload, map<string|string[]> headers) returns AssistantObject|errorModifies an assistant.
Parameters
- payload ModifyAssistantRequest -
Return Type
- AssistantObject|error - OK
delete assistants/[string assistantId]
function delete assistants/[string assistantId](map<string|string[]> headers) returns DeleteAssistantResponse|errorDelete an assistant.
Return Type
post audio/speech
function post audio/speech(CreateSpeechRequest payload, map<string|string[]> headers) returns byte[]|errorGenerates audio from the input text.
Parameters
- payload CreateSpeechRequest -
Return Type
- byte[]|error - OK
post audio/transcriptions
function post audio/transcriptions(CreateTranscriptionRequest payload, map<string|string[]> headers) returns InlineResponse200|errorTranscribes audio into the input language.
Parameters
- payload CreateTranscriptionRequest -
Return Type
- InlineResponse200|error - OK
post audio/translations
function post audio/translations(CreateTranslationRequest payload, map<string|string[]> headers) returns InlineResponse2001|errorTranslates audio into English.
Parameters
- payload CreateTranslationRequest -
Return Type
- InlineResponse2001|error - OK
get batches
function get batches(map<string|string[]> headers, *ListBatchesQueries queries) returns ListBatchesResponse|errorList your organization's batches.
Parameters
- queries *ListBatchesQueries - Queries to be sent with the request
Return Type
- ListBatchesResponse|error - Batch listed successfully
post batches
Creates and executes a batch from an uploaded file of requests
Parameters
- payload BatchesBody -
get batches/[string batchId]
Retrieves a batch.
post batches/[string batchId]/cancel
Cancels an in-progress batch. The batch will be in status cancelling for up to 10 minutes, before changing to cancelled, where it will have partial results (if any) available in the output file.
get chat/completions
function get chat/completions(map<string|string[]> headers, *ListChatCompletionsQueries queries) returns ChatCompletionList|errorList stored Chat Completions. Only Chat Completions that have been stored
with the store parameter set to true will be returned.
Parameters
- queries *ListChatCompletionsQueries - Queries to be sent with the request
Return Type
- ChatCompletionList|error - A list of Chat Completions
post chat/completions
function post chat/completions(CreateChatCompletionRequest payload, map<string|string[]> headers) returns CreateChatCompletionResponse|errorStarting a new project? We recommend trying Responses to take advantage of the latest OpenAI platform features. Compare Chat Completions with Responses.
Creates a model response for the given chat conversation. Learn more in the text generation, vision, and audio guides.
Parameter support can differ depending on the model used to generate the response, particularly for newer reasoning models. Parameters that are only supported for reasoning models are noted below. For the current state of unsupported parameters in reasoning models, refer to the reasoning guide.
Parameters
- payload CreateChatCompletionRequest -
Return Type
get chat/completions/[string completionId]
function get chat/completions/[string completionId](map<string|string[]> headers) returns CreateChatCompletionResponse|errorGet a stored chat completion. Only Chat Completions that have been created
with the store parameter set to true will be returned.
Return Type
- CreateChatCompletionResponse|error - A chat completion
post chat/completions/[string completionId]
function post chat/completions/[string completionId](CompletionscompletionIdBody payload, map<string|string[]> headers) returns CreateChatCompletionResponse|errorModify a stored chat completion. Only Chat Completions that have been
created with the store parameter set to true can be modified. Currently,
the only supported modification is to update the metadata field.
Parameters
- payload CompletionscompletionIdBody -
Return Type
- CreateChatCompletionResponse|error - A chat completion
delete chat/completions/[string completionId]
function delete chat/completions/[string completionId](map<string|string[]> headers) returns ChatCompletionDeleted|errorDelete a stored chat completion. Only Chat Completions that have been
created with the store parameter set to true can be deleted.
Return Type
- ChatCompletionDeleted|error - The chat completion was deleted successfully
get chat/completions/[string completionId]/messages
function get chat/completions/[string completionId]/messages(map<string|string[]> headers, *GetChatCompletionMessagesQueries queries) returns ChatCompletionMessageList|errorGet the messages in a stored chat completion. Only Chat Completions that
have been created with the store parameter set to true will be
returned.
Parameters
- queries *GetChatCompletionMessagesQueries - Queries to be sent with the request
Return Type
- ChatCompletionMessageList|error - A list of messages
post completions
function post completions(CreateCompletionRequest payload, map<string|string[]> headers) returns CreateCompletionResponse|errorCreates a completion for the provided prompt and parameters.
Parameters
- payload CreateCompletionRequest -
Return Type
post embeddings
function post embeddings(CreateEmbeddingRequest payload, map<string|string[]> headers) returns CreateEmbeddingResponse|errorCreates an embedding vector representing the input text.
Parameters
- payload CreateEmbeddingRequest -
Return Type
get evals
List evaluations for a project.
Parameters
- queries *ListEvalsQueries - Queries to be sent with the request
post evals
Create the structure of an evaluation that can be used to test a model's performance. An evaluation is a set of testing criteria and a datasource. After creating an evaluation, you can run it on different models and model parameters. We support several types of graders and datasources. For more information, see the Evals guide.
Parameters
- payload CreateEvalRequest -
get evals/[string evalId]
Get an evaluation by ID.
post evals/[string evalId]
function post evals/[string evalId](EvalsevalIdBody payload, map<string|string[]> headers) returns Eval|errorUpdate certain properties of an evaluation.
Parameters
- payload EvalsevalIdBody - Request to update an evaluation
delete evals/[string evalId]
function delete evals/[string evalId](map<string|string[]> headers) returns InlineResponse2002|errorDelete an evaluation.
Return Type
- InlineResponse2002|error - Successfully deleted the evaluation
get evals/[string evalId]/runs
function get evals/[string evalId]/runs(map<string|string[]> headers, *GetEvalRunsQueries queries) returns EvalRunList|errorGet a list of runs for an evaluation.
Parameters
- queries *GetEvalRunsQueries - Queries to be sent with the request
Return Type
- EvalRunList|error - A list of runs for the evaluation
post evals/[string evalId]/runs
function post evals/[string evalId]/runs(CreateEvalRunRequest payload, map<string|string[]> headers) returns EvalRun|errorCreate a new evaluation run. This is the endpoint that will kick off grading.
Parameters
- payload CreateEvalRunRequest -
get evals/[string evalId]/runs/[string runId]
function get evals/[string evalId]/runs/[string runId](map<string|string[]> headers) returns EvalRun|errorGet an evaluation run by ID.
post evals/[string evalId]/runs/[string runId]
function post evals/[string evalId]/runs/[string runId](map<string|string[]> headers) returns EvalRun|errorCancel an ongoing evaluation run.
delete evals/[string evalId]/runs/[string runId]
function delete evals/[string evalId]/runs/[string runId](map<string|string[]> headers) returns InlineResponse2003|errorDelete an eval run.
Return Type
- InlineResponse2003|error - Successfully deleted the eval run
get evals/[string evalId]/runs/[string runId]/output_items
function get evals/[string evalId]/runs/[string runId]/output_items(map<string|string[]> headers, *GetEvalRunOutputItemsQueries queries) returns EvalRunOutputItemList|errorGet a list of output items for an evaluation run.
Parameters
- queries *GetEvalRunOutputItemsQueries - Queries to be sent with the request
Return Type
- EvalRunOutputItemList|error - A list of output items for the evaluation run
get evals/[string evalId]/runs/[string runId]/output_items/[string outputItemId]
function get evals/[string evalId]/runs/[string runId]/output_items/[string outputItemId](map<string|string[]> headers) returns EvalRunOutputItem|errorGet an evaluation run output item by ID.
Return Type
- EvalRunOutputItem|error - The evaluation run output item
get files
function get files(map<string|string[]> headers, *ListFilesQueries queries) returns ListFilesResponse|errorReturns a list of files.
Parameters
- queries *ListFilesQueries - Queries to be sent with the request
Return Type
- ListFilesResponse|error - OK
post files
function post files(CreateFileRequest payload, map<string|string[]> headers) returns OpenAIFile|errorUpload a file that can be used across various endpoints. Individual files can be up to 512 MB, and the size of all files uploaded by one organization can be up to 100 GB.
The Assistants API supports files up to 2 million tokens and of specific file types. See the Assistants Tools guide for details.
The Fine-tuning API only supports .jsonl files. The input also has certain required formats for fine-tuning chat or completions models.
The Batch API only supports .jsonl files up to 200 MB in size. The input also has a specific required format.
Please contact us if you need to increase these storage limits.
Parameters
- payload CreateFileRequest -
Return Type
- OpenAIFile|error - OK
get files/[string fileId]
function get files/[string fileId](map<string|string[]> headers) returns OpenAIFile|errorReturns information about a specific file.
Return Type
- OpenAIFile|error - OK
delete files/[string fileId]
function delete files/[string fileId](map<string|string[]> headers) returns DeleteFileResponse|errorDelete a file.
Return Type
- DeleteFileResponse|error - OK
get files/[string fileId]/content
Returns the contents of the specified file.
get fine_tuning/checkpoints/[string fineTunedModelCheckpoint]/permissions
function get fine_tuning/checkpoints/[string fineTunedModelCheckpoint]/permissions(map<string|string[]> headers, *ListFineTuningCheckpointPermissionsQueries queries) returns ListFineTuningCheckpointPermissionResponse|errorNOTE: This endpoint requires an admin API key.
Organization owners can use this endpoint to view all permissions for a fine-tuned model checkpoint.
Parameters
- queries *ListFineTuningCheckpointPermissionsQueries - Queries to be sent with the request
Return Type
post fine_tuning/checkpoints/[string fineTunedModelCheckpoint]/permissions
function post fine_tuning/checkpoints/[string fineTunedModelCheckpoint]/permissions(CreateFineTuningCheckpointPermissionRequest payload, map<string|string[]> headers) returns ListFineTuningCheckpointPermissionResponse|errorNOTE: Calling this endpoint requires an admin API key.
This enables organization owners to share fine-tuned models with other projects in their organization.
Parameters
Return Type
delete fine_tuning/checkpoints/[string fineTunedModelCheckpoint]/permissions/[string permissionId]
function delete fine_tuning/checkpoints/[string fineTunedModelCheckpoint]/permissions/[string permissionId](map<string|string[]> headers) returns DeleteFineTuningCheckpointPermissionResponse|errorNOTE: This endpoint requires an admin API key.
Organization owners can use this endpoint to delete a permission for a fine-tuned model checkpoint.
Return Type
get fine_tuning/jobs
function get fine_tuning/jobs(map<string|string[]> headers, *ListPaginatedFineTuningJobsQueries queries) returns ListPaginatedFineTuningJobsResponse|errorList your organization's fine-tuning jobs
Parameters
- queries *ListPaginatedFineTuningJobsQueries - Queries to be sent with the request
Return Type
post fine_tuning/jobs
function post fine_tuning/jobs(CreateFineTuningJobRequest payload, map<string|string[]> headers) returns FineTuningJob|errorCreates a fine-tuning job which begins the process of creating a new model from a given dataset.
Response includes details of the enqueued job including job status and the name of the fine-tuned models once complete.
Parameters
- payload CreateFineTuningJobRequest -
Return Type
- FineTuningJob|error - OK
get fine_tuning/jobs/[string fineTuningJobId]
function get fine_tuning/jobs/[string fineTuningJobId](map<string|string[]> headers) returns FineTuningJob|errorGet info about a fine-tuning job.
Return Type
- FineTuningJob|error - OK
post fine_tuning/jobs/[string fineTuningJobId]/cancel
function post fine_tuning/jobs/[string fineTuningJobId]/cancel(map<string|string[]> headers) returns FineTuningJob|errorImmediately cancel a fine-tune job.
Return Type
- FineTuningJob|error - OK
get fine_tuning/jobs/[string fineTuningJobId]/checkpoints
function get fine_tuning/jobs/[string fineTuningJobId]/checkpoints(map<string|string[]> headers, *ListFineTuningJobCheckpointsQueries queries) returns ListFineTuningJobCheckpointsResponse|errorList checkpoints for a fine-tuning job.
Parameters
- queries *ListFineTuningJobCheckpointsQueries - Queries to be sent with the request
Return Type
get fine_tuning/jobs/[string fineTuningJobId]/events
function get fine_tuning/jobs/[string fineTuningJobId]/events(map<string|string[]> headers, *ListFineTuningEventsQueries queries) returns ListFineTuningJobEventsResponse|errorGet status updates for a fine-tuning job.
Parameters
- queries *ListFineTuningEventsQueries - Queries to be sent with the request
Return Type
post images/edits
function post images/edits(CreateImageEditRequest payload, map<string|string[]> headers) returns ImagesResponse|errorCreates an edited or extended image given one or more source images and a prompt. This endpoint only supports gpt-image-1 and dall-e-2.
Parameters
- payload CreateImageEditRequest -
Return Type
- ImagesResponse|error - OK
post images/generations
function post images/generations(CreateImageRequest payload, map<string|string[]> headers) returns ImagesResponse|errorCreates an image given a prompt. Learn more.
Parameters
- payload CreateImageRequest -
Return Type
- ImagesResponse|error - OK
post images/variations
function post images/variations(CreateImageVariationRequest payload, map<string|string[]> headers) returns ImagesResponse|errorCreates a variation of a given image. This endpoint only supports dall-e-2.
Parameters
- payload CreateImageVariationRequest -
Return Type
- ImagesResponse|error - OK
get models
function get models(map<string|string[]> headers) returns ListModelsResponse|errorLists the currently available models, and provides basic information about each one such as the owner and availability.
Return Type
- ListModelsResponse|error - OK
get models/[string model]
Retrieves a model instance, providing basic information about the model such as the owner and permissioning.
delete models/[string model]
function delete models/[string model](map<string|string[]> headers) returns DeleteModelResponse|errorDelete a fine-tuned model. You must have the Owner role in your organization to delete a model.
Return Type
- DeleteModelResponse|error - OK
post moderations
function post moderations(CreateModerationRequest payload, map<string|string[]> headers) returns CreateModerationResponse|errorClassifies if text and/or image inputs are potentially harmful. Learn more in the moderation guide.
Parameters
- payload CreateModerationRequest -
Return Type
get organization/admin_api_keys
function get organization/admin_api_keys(map<string|string[]> headers, *AdminApiKeysListQueries queries) returns ApiKeyList|errorList organization API keys
Parameters
- queries *AdminApiKeysListQueries - Queries to be sent with the request
Return Type
- ApiKeyList|error - A list of organization API keys
post organization/admin_api_keys
function post organization/admin_api_keys(OrganizationAdminApiKeysBody payload, map<string|string[]> headers) returns AdminApiKey|errorCreate an organization admin API key
Parameters
- payload OrganizationAdminApiKeysBody -
Return Type
- AdminApiKey|error - The newly created admin API key
get organization/admin_api_keys/[string keyId]
function get organization/admin_api_keys/[string keyId](map<string|string[]> headers) returns AdminApiKey|errorRetrieve a single organization API key
Return Type
- AdminApiKey|error - Details of the requested API key
delete organization/admin_api_keys/[string keyId]
function delete organization/admin_api_keys/[string keyId](map<string|string[]> headers) returns InlineResponse2004|errorDelete an organization admin API key
Return Type
- InlineResponse2004|error - Confirmation that the API key was deleted
get organization/audit_logs
function get organization/audit_logs(map<string|string[]> headers, *ListAuditLogsQueries queries) returns ListAuditLogsResponse|errorList user actions and configuration changes within this organization.
Parameters
- queries *ListAuditLogsQueries - Queries to be sent with the request
Return Type
- ListAuditLogsResponse|error - Audit logs listed successfully
get organization/certificates
function get organization/certificates(map<string|string[]> headers, *ListOrganizationCertificatesQueries queries) returns ListCertificatesResponse|errorList uploaded certificates for this organization.
Parameters
- queries *ListOrganizationCertificatesQueries - Queries to be sent with the request
Return Type
- ListCertificatesResponse|error - Certificates listed successfully
post organization/certificates
function post organization/certificates(UploadCertificateRequest payload, map<string|string[]> headers) returns Certificate|errorUpload a certificate to the organization. This does not automatically activate the certificate.
Organizations can upload up to 50 certificates.
Parameters
- payload UploadCertificateRequest - The certificate upload payload
Return Type
- Certificate|error - Certificate uploaded successfully
post organization/certificates/activate
function post organization/certificates/activate(ToggleCertificatesRequest payload, map<string|string[]> headers) returns ListCertificatesResponse|errorActivate certificates at the organization level.
You can atomically and idempotently activate up to 10 certificates at a time.
Parameters
- payload ToggleCertificatesRequest - The certificate activation payload
Return Type
- ListCertificatesResponse|error - Certificates activated successfully
post organization/certificates/deactivate
function post organization/certificates/deactivate(ToggleCertificatesRequest payload, map<string|string[]> headers) returns ListCertificatesResponse|errorDeactivate certificates at the organization level.
You can atomically and idempotently deactivate up to 10 certificates at a time.
Parameters
- payload ToggleCertificatesRequest - The certificate deactivation payload
Return Type
- ListCertificatesResponse|error - Certificates deactivated successfully
get organization/certificates/[string certificateId]
function get organization/certificates/[string certificateId](map<string|string[]> headers, *GetCertificateQueries queries) returns Certificate|errorGet a certificate that has been uploaded to the organization.
You can get a certificate regardless of whether it is active or not.
Parameters
- queries *GetCertificateQueries - Queries to be sent with the request
Return Type
- Certificate|error - Certificate retrieved successfully
post organization/certificates/[string certificateId]
function post organization/certificates/[string certificateId](ModifyCertificateRequest payload, map<string|string[]> headers) returns Certificate|errorModify a certificate. Note that only the name can be modified.
Parameters
- payload ModifyCertificateRequest - The certificate modification payload
Return Type
- Certificate|error - Certificate modified successfully
delete organization/certificates/[string certificateId]
function delete organization/certificates/[string certificateId](map<string|string[]> headers) returns DeleteCertificateResponse|errorDelete a certificate from the organization.
The certificate must be inactive for the organization and all projects.
Return Type
- DeleteCertificateResponse|error - Certificate deleted successfully
get organization/costs
function get organization/costs(map<string|string[]> headers, *UsageCostsQueries queries) returns UsageResponse|errorGet costs details for the organization.
Parameters
- queries *UsageCostsQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Costs data retrieved successfully
get organization/invites
function get organization/invites(map<string|string[]> headers, *ListInvitesQueries queries) returns InviteListResponse|errorReturns a list of invites in the organization.
Parameters
- queries *ListInvitesQueries - Queries to be sent with the request
Return Type
- InviteListResponse|error - Invites listed successfully
post organization/invites
function post organization/invites(InviteRequest payload, map<string|string[]> headers) returns Invite|errorCreate an invite for a user to the organization. The invite must be accepted by the user before they have access to the organization.
Parameters
- payload InviteRequest - The invite request payload
get organization/invites/[string inviteId]
function get organization/invites/[string inviteId](map<string|string[]> headers) returns Invite|errorRetrieves an invite.
delete organization/invites/[string inviteId]
function delete organization/invites/[string inviteId](map<string|string[]> headers) returns InviteDeleteResponse|errorDelete an invite. If the invite has already been accepted, it cannot be deleted.
Return Type
- InviteDeleteResponse|error - Invite deleted successfully
get organization/projects
function get organization/projects(map<string|string[]> headers, *ListProjectsQueries queries) returns ProjectListResponse|errorReturns a list of projects.
Parameters
- queries *ListProjectsQueries - Queries to be sent with the request
Return Type
- ProjectListResponse|error - Projects listed successfully
post organization/projects
function post organization/projects(ProjectCreateRequest payload, map<string|string[]> headers) returns Project|errorCreate a new project in the organization. Projects can be created and archived, but cannot be deleted.
Parameters
- payload ProjectCreateRequest - The project create request payload
get organization/projects/[string projectId]
function get organization/projects/[string projectId](map<string|string[]> headers) returns Project|errorRetrieves a project.
post organization/projects/[string projectId]
function post organization/projects/[string projectId](ProjectUpdateRequest payload, map<string|string[]> headers) returns Project|errorModifies a project in the organization.
Parameters
- payload ProjectUpdateRequest - The project update request payload
get organization/projects/[string projectId]/api_keys
function get organization/projects/[string projectId]/api_keys(map<string|string[]> headers, *ListProjectApiKeysQueries queries) returns ProjectApiKeyListResponse|errorReturns a list of API keys in the project.
Parameters
- queries *ListProjectApiKeysQueries - Queries to be sent with the request
Return Type
- ProjectApiKeyListResponse|error - Project API keys listed successfully
get organization/projects/[string projectId]/api_keys/[string keyId]
function get organization/projects/[string projectId]/api_keys/[string keyId](map<string|string[]> headers) returns ProjectApiKey|errorRetrieves an API key in the project.
Return Type
- ProjectApiKey|error - Project API key retrieved successfully
delete organization/projects/[string projectId]/api_keys/[string keyId]
function delete organization/projects/[string projectId]/api_keys/[string keyId](map<string|string[]> headers) returns ProjectApiKeyDeleteResponse|errorDeletes an API key from the project.
Return Type
- ProjectApiKeyDeleteResponse|error - Project API key deleted successfully
post organization/projects/[string projectId]/archive
function post organization/projects/[string projectId]/archive(map<string|string[]> headers) returns Project|errorArchives a project in the organization. Archived projects cannot be used or updated.
get organization/projects/[string projectId]/certificates
function get organization/projects/[string projectId]/certificates(map<string|string[]> headers, *ListProjectCertificatesQueries queries) returns ListCertificatesResponse|errorList certificates for this project.
Parameters
- queries *ListProjectCertificatesQueries - Queries to be sent with the request
Return Type
- ListCertificatesResponse|error - Certificates listed successfully
post organization/projects/[string projectId]/certificates/activate
function post organization/projects/[string projectId]/certificates/activate(ToggleCertificatesRequest payload, map<string|string[]> headers) returns ListCertificatesResponse|errorActivate certificates at the project level.
You can atomically and idempotently activate up to 10 certificates at a time.
Parameters
- payload ToggleCertificatesRequest - The certificate activation payload
Return Type
- ListCertificatesResponse|error - Certificates activated successfully
post organization/projects/[string projectId]/certificates/deactivate
function post organization/projects/[string projectId]/certificates/deactivate(ToggleCertificatesRequest payload, map<string|string[]> headers) returns ListCertificatesResponse|errorDeactivate certificates at the project level.
You can atomically and idempotently deactivate up to 10 certificates at a time.
Parameters
- payload ToggleCertificatesRequest - The certificate deactivation payload
Return Type
- ListCertificatesResponse|error - Certificates deactivated successfully
get organization/projects/[string projectId]/rate_limits
function get organization/projects/[string projectId]/rate_limits(map<string|string[]> headers, *ListProjectRateLimitsQueries queries) returns ProjectRateLimitListResponse|errorReturns the rate limits per model for a project.
Parameters
- queries *ListProjectRateLimitsQueries - Queries to be sent with the request
Return Type
- ProjectRateLimitListResponse|error - Project rate limits listed successfully
post organization/projects/[string projectId]/rate_limits/[string rateLimitId]
function post organization/projects/[string projectId]/rate_limits/[string rateLimitId](ProjectRateLimitUpdateRequest payload, map<string|string[]> headers) returns ProjectRateLimit|errorUpdates a project rate limit.
Parameters
- payload ProjectRateLimitUpdateRequest - The project rate limit update request payload
Return Type
- ProjectRateLimit|error - Project rate limit updated successfully
get organization/projects/[string projectId]/service_accounts
function get organization/projects/[string projectId]/service_accounts(map<string|string[]> headers, *ListProjectServiceAccountsQueries queries) returns ProjectServiceAccountListResponse|errorReturns a list of service accounts in the project.
Parameters
- queries *ListProjectServiceAccountsQueries - Queries to be sent with the request
Return Type
- ProjectServiceAccountListResponse|error - Project service accounts listed successfully
post organization/projects/[string projectId]/service_accounts
function post organization/projects/[string projectId]/service_accounts(ProjectServiceAccountCreateRequest payload, map<string|string[]> headers) returns ProjectServiceAccountCreateResponse|errorCreates a new service account in the project. This also returns an unredacted API key for the service account.
Parameters
- payload ProjectServiceAccountCreateRequest - The project service account create request payload
Return Type
- ProjectServiceAccountCreateResponse|error - Project service account created successfully
get organization/projects/[string projectId]/service_accounts/[string serviceAccountId]
function get organization/projects/[string projectId]/service_accounts/[string serviceAccountId](map<string|string[]> headers) returns ProjectServiceAccount|errorRetrieves a service account in the project.
Return Type
- ProjectServiceAccount|error - Project service account retrieved successfully
delete organization/projects/[string projectId]/service_accounts/[string serviceAccountId]
function delete organization/projects/[string projectId]/service_accounts/[string serviceAccountId](map<string|string[]> headers) returns ProjectServiceAccountDeleteResponse|errorDeletes a service account from the project.
Return Type
- ProjectServiceAccountDeleteResponse|error - Project service account deleted successfully
get organization/projects/[string projectId]/users
function get organization/projects/[string projectId]/users(map<string|string[]> headers, *ListProjectUsersQueries queries) returns ProjectUserListResponse|errorReturns a list of users in the project.
Parameters
- queries *ListProjectUsersQueries - Queries to be sent with the request
Return Type
- ProjectUserListResponse|error - Project users listed successfully
post organization/projects/[string projectId]/users
function post organization/projects/[string projectId]/users(ProjectUserCreateRequest payload, map<string|string[]> headers) returns ProjectUser|errorAdds a user to the project. Users must already be members of the organization to be added to a project.
Parameters
- payload ProjectUserCreateRequest - The project user create request payload
Return Type
- ProjectUser|error - User added to project successfully
get organization/projects/[string projectId]/users/[string userId]
function get organization/projects/[string projectId]/users/[string userId](map<string|string[]> headers) returns ProjectUser|errorRetrieves a user in the project.
Return Type
- ProjectUser|error - Project user retrieved successfully
post organization/projects/[string projectId]/users/[string userId]
function post organization/projects/[string projectId]/users/[string userId](ProjectUserUpdateRequest payload, map<string|string[]> headers) returns ProjectUser|errorModifies a user's role in the project.
Parameters
- payload ProjectUserUpdateRequest - The project user update request payload
Return Type
- ProjectUser|error - Project user's role updated successfully
delete organization/projects/[string projectId]/users/[string userId]
function delete organization/projects/[string projectId]/users/[string userId](map<string|string[]> headers) returns ProjectUserDeleteResponse|errorDeletes a user from the project.
Return Type
- ProjectUserDeleteResponse|error - Project user deleted successfully
get organization/usage/audio_speeches
function get organization/usage/audio_speeches(map<string|string[]> headers, *UsageAudioSpeechesQueries queries) returns UsageResponse|errorGet audio speeches usage details for the organization.
Parameters
- queries *UsageAudioSpeechesQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/audio_transcriptions
function get organization/usage/audio_transcriptions(map<string|string[]> headers, *UsageAudioTranscriptionsQueries queries) returns UsageResponse|errorGet audio transcriptions usage details for the organization.
Parameters
- queries *UsageAudioTranscriptionsQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/code_interpreter_sessions
function get organization/usage/code_interpreter_sessions(map<string|string[]> headers, *UsageCodeInterpreterSessionsQueries queries) returns UsageResponse|errorGet code interpreter sessions usage details for the organization.
Parameters
- queries *UsageCodeInterpreterSessionsQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/completions
function get organization/usage/completions(map<string|string[]> headers, *UsageCompletionsQueries queries) returns UsageResponse|errorGet completions usage details for the organization.
Parameters
- queries *UsageCompletionsQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/embeddings
function get organization/usage/embeddings(map<string|string[]> headers, *UsageEmbeddingsQueries queries) returns UsageResponse|errorGet embeddings usage details for the organization.
Parameters
- queries *UsageEmbeddingsQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/images
function get organization/usage/images(map<string|string[]> headers, *UsageImagesQueries queries) returns UsageResponse|errorGet images usage details for the organization.
Parameters
- queries *UsageImagesQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/moderations
function get organization/usage/moderations(map<string|string[]> headers, *UsageModerationsQueries queries) returns UsageResponse|errorGet moderations usage details for the organization.
Parameters
- queries *UsageModerationsQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/usage/vector_stores
function get organization/usage/vector_stores(map<string|string[]> headers, *UsageVectorStoresQueries queries) returns UsageResponse|errorGet vector stores usage details for the organization.
Parameters
- queries *UsageVectorStoresQueries - Queries to be sent with the request
Return Type
- UsageResponse|error - Usage data retrieved successfully
get organization/users
function get organization/users(map<string|string[]> headers, *ListUsersQueries queries) returns UserListResponse|errorLists all of the users in the organization.
Parameters
- queries *ListUsersQueries - Queries to be sent with the request
Return Type
- UserListResponse|error - Users listed successfully
get organization/users/[string userId]
Retrieves a user by their identifier.
post organization/users/[string userId]
function post organization/users/[string userId](UserRoleUpdateRequest payload, map<string|string[]> headers) returns User|errorModifies a user's role in the organization.
Parameters
- payload UserRoleUpdateRequest - The new user role to modify. This must be one of
ownerormember
delete organization/users/[string userId]
function delete organization/users/[string userId](map<string|string[]> headers) returns UserDeleteResponse|errorDeletes a user from the organization.
Return Type
- UserDeleteResponse|error - User deleted successfully
post realtime/sessions
function post realtime/sessions(RealtimeSessionCreateRequest payload, map<string|string[]> headers) returns RealtimeSessionCreateResponse|errorCreate an ephemeral API token for use in client-side applications with the
Realtime API. Can be configured with the same session parameters as the
session.update client event.
It responds with a session object, plus a client_secret key which contains
a usable ephemeral API token that can be used to authenticate browser clients
for the Realtime API.
Parameters
- payload RealtimeSessionCreateRequest - Create an ephemeral API key with the given session configuration
Return Type
- RealtimeSessionCreateResponse|error - Session created successfully
post realtime/transcription_sessions
function post realtime/transcription_sessions(RealtimeTranscriptionSessionCreateRequest payload, map<string|string[]> headers) returns RealtimeTranscriptionSessionCreateResponse|errorCreate an ephemeral API token for use in client-side applications with the
Realtime API specifically for realtime transcriptions.
Can be configured with the same session parameters as the transcription_session.update client event.
It responds with a session object, plus a client_secret key which contains
a usable ephemeral API token that can be used to authenticate browser clients
for the Realtime API.
Parameters
- payload RealtimeTranscriptionSessionCreateRequest - Create an ephemeral API key with the given session configuration
Return Type
- RealtimeTranscriptionSessionCreateResponse|error - Session created successfully
post responses
function post responses(CreateResponse payload, map<string|string[]> headers) returns Response|errorCreates a model response. Provide text or image inputs to generate text or JSON outputs. Have the model call your own custom code or use built-in tools like web search or file search to use your own data as input for the model's response.
Parameters
- payload CreateResponse -
get responses/[string responseId]
function get responses/[string responseId](map<string|string[]> headers, *GetResponseQueries queries) returns Response|errorRetrieves a model response with the given ID.
Parameters
- queries *GetResponseQueries - Queries to be sent with the request
delete responses/[string responseId]
Deletes a model response with the given ID.
Return Type
- error? - OK
get responses/[string responseId]/input_items
function get responses/[string responseId]/input_items(map<string|string[]> headers, *ListInputItemsQueries queries) returns ResponseItemList|errorReturns a list of input items for a given response.
Parameters
- queries *ListInputItemsQueries - Queries to be sent with the request
Return Type
- ResponseItemList|error - OK
post threads
function post threads(CreateThreadRequest payload, map<string|string[]> headers) returns ThreadObject|errorCreate a thread.
Parameters
- payload CreateThreadRequest -
Return Type
- ThreadObject|error - OK
post threads/runs
function post threads/runs(CreateThreadAndRunRequest payload, map<string|string[]> headers) returns RunObject|errorCreate a thread and run it in one request.
Parameters
- payload CreateThreadAndRunRequest -
get threads/[string threadId]
function get threads/[string threadId](map<string|string[]> headers) returns ThreadObject|errorRetrieves a thread.
Return Type
- ThreadObject|error - OK
post threads/[string threadId]
function post threads/[string threadId](ModifyThreadRequest payload, map<string|string[]> headers) returns ThreadObject|errorModifies a thread.
Parameters
- payload ModifyThreadRequest -
Return Type
- ThreadObject|error - OK
delete threads/[string threadId]
function delete threads/[string threadId](map<string|string[]> headers) returns DeleteThreadResponse|errorDelete a thread.
Return Type
get threads/[string threadId]/messages
function get threads/[string threadId]/messages(map<string|string[]> headers, *ListMessagesQueries queries) returns ListMessagesResponse|errorReturns a list of messages for a given thread.
Parameters
- queries *ListMessagesQueries - Queries to be sent with the request
Return Type
post threads/[string threadId]/messages
function post threads/[string threadId]/messages(CreateMessageRequest payload, map<string|string[]> headers) returns MessageObject|errorCreate a message.
Parameters
- payload CreateMessageRequest -
Return Type
- MessageObject|error - OK
get threads/[string threadId]/messages/[string messageId]
function get threads/[string threadId]/messages/[string messageId](map<string|string[]> headers) returns MessageObject|errorRetrieve a message.
Return Type
- MessageObject|error - OK
post threads/[string threadId]/messages/[string messageId]
function post threads/[string threadId]/messages/[string messageId](ModifyMessageRequest payload, map<string|string[]> headers) returns MessageObject|errorModifies a message.
Parameters
- payload ModifyMessageRequest -
Return Type
- MessageObject|error - OK
delete threads/[string threadId]/messages/[string messageId]
function delete threads/[string threadId]/messages/[string messageId](map<string|string[]> headers) returns DeleteMessageResponse|errorDeletes a message.
Return Type
get threads/[string threadId]/runs
function get threads/[string threadId]/runs(map<string|string[]> headers, *ListRunsQueries queries) returns ListRunsResponse|errorReturns a list of runs belonging to a thread.
Parameters
- queries *ListRunsQueries - Queries to be sent with the request
Return Type
- ListRunsResponse|error - OK
post threads/[string threadId]/runs
function post threads/[string threadId]/runs(CreateRunRequest payload, map<string|string[]> headers, *CreateRunQueries queries) returns RunObject|errorCreate a run.
Parameters
- payload CreateRunRequest -
- queries *CreateRunQueries - Queries to be sent with the request
get threads/[string threadId]/runs/[string runId]
function get threads/[string threadId]/runs/[string runId](map<string|string[]> headers) returns RunObject|errorRetrieves a run.
post threads/[string threadId]/runs/[string runId]
function post threads/[string threadId]/runs/[string runId](ModifyRunRequest payload, map<string|string[]> headers) returns RunObject|errorModifies a run.
Parameters
- payload ModifyRunRequest -
post threads/[string threadId]/runs/[string runId]/cancel
function post threads/[string threadId]/runs/[string runId]/cancel(map<string|string[]> headers) returns RunObject|errorCancels a run that is in_progress.
get threads/[string threadId]/runs/[string runId]/steps
function get threads/[string threadId]/runs/[string runId]/steps(map<string|string[]> headers, *ListRunStepsQueries queries) returns ListRunStepsResponse|errorReturns a list of run steps belonging to a run.
Parameters
- queries *ListRunStepsQueries - Queries to be sent with the request
Return Type
get threads/[string threadId]/runs/[string runId]/steps/[string stepId]
function get threads/[string threadId]/runs/[string runId]/steps/[string stepId](map<string|string[]> headers, *GetRunStepQueries queries) returns RunStepObject|errorRetrieves a run step.
Parameters
- queries *GetRunStepQueries - Queries to be sent with the request
Return Type
- RunStepObject|error - OK
post threads/[string threadId]/runs/[string runId]/submit_tool_outputs
function post threads/[string threadId]/runs/[string runId]/submit_tool_outputs(SubmitToolOutputsRunRequest payload, map<string|string[]> headers) returns RunObject|errorWhen a run has the status: "requires_action" and required_action.type is submit_tool_outputs, this endpoint can be used to submit the outputs from the tool calls once they're all completed. All outputs must be submitted in a single request.
Parameters
- payload SubmitToolOutputsRunRequest -
post uploads
function post uploads(CreateUploadRequest payload, map<string|string[]> headers) returns Upload|errorCreates an intermediate Upload object that you can add Parts to. Currently, an Upload can accept at most 8 GB in total and expires after an hour after you create it.
Once you complete the Upload, we will create a File object that contains all the parts you uploaded. This File is usable in the rest of our platform as a regular File object.
For certain purpose values, the correct mime_type must be specified.
Please refer to documentation for the
supported MIME types for your use case.
For guidance on the proper filename extensions for each purpose, please follow the documentation on creating a File.
Parameters
- payload CreateUploadRequest -
post uploads/[string uploadId]/cancel
Cancels the Upload. No Parts may be added after an Upload is cancelled.
post uploads/[string uploadId]/complete
function post uploads/[string uploadId]/complete(CompleteUploadRequest payload, map<string|string[]> headers) returns Upload|errorCompletes the Upload.
Within the returned Upload object, there is a nested File object that is ready to use in the rest of the platform.
You can specify the order of the Parts by passing in an ordered list of the Part IDs.
The number of bytes uploaded upon completion must match the number of bytes initially specified when creating the Upload object. No Parts may be added after an Upload is completed.
Parameters
- payload CompleteUploadRequest -
post uploads/[string uploadId]/parts
function post uploads/[string uploadId]/parts(AddUploadPartRequest payload, map<string|string[]> headers) returns UploadPart|errorAdds a Part to an Upload object. A Part represents a chunk of bytes from the file you are trying to upload.
Each Part can be at most 64 MB, and you can add Parts until you hit the Upload maximum of 8 GB.
It is possible to add multiple Parts in parallel. You can decide the intended order of the Parts when you complete the Upload.
Parameters
- payload AddUploadPartRequest -
Return Type
- UploadPart|error - OK
get vector_stores
function get vector_stores(map<string|string[]> headers, *ListVectorStoresQueries queries) returns ListVectorStoresResponse|errorReturns a list of vector stores.
Parameters
- queries *ListVectorStoresQueries - Queries to be sent with the request
Return Type
post vector_stores
function post vector_stores(CreateVectorStoreRequest payload, map<string|string[]> headers) returns VectorStoreObject|errorCreate a vector store.
Parameters
- payload CreateVectorStoreRequest -
Return Type
- VectorStoreObject|error - OK
get vector_stores/[string vectorStoreId]
function get vector_stores/[string vectorStoreId](map<string|string[]> headers) returns VectorStoreObject|errorRetrieves a vector store.
Return Type
- VectorStoreObject|error - OK
post vector_stores/[string vectorStoreId]
function post vector_stores/[string vectorStoreId](UpdateVectorStoreRequest payload, map<string|string[]> headers) returns VectorStoreObject|errorModifies a vector store.
Parameters
- payload UpdateVectorStoreRequest -
Return Type
- VectorStoreObject|error - OK
delete vector_stores/[string vectorStoreId]
function delete vector_stores/[string vectorStoreId](map<string|string[]> headers) returns DeleteVectorStoreResponse|errorDelete a vector store.
Return Type
post vector_stores/[string vectorStoreId]/file_batches
function post vector_stores/[string vectorStoreId]/file_batches(CreateVectorStoreFileBatchRequest payload, map<string|string[]> headers) returns VectorStoreFileBatchObject|errorCreate a vector store file batch.
Parameters
- payload CreateVectorStoreFileBatchRequest -
Return Type
get vector_stores/[string vectorStoreId]/file_batches/[string batchId]
function get vector_stores/[string vectorStoreId]/file_batches/[string batchId](map<string|string[]> headers) returns VectorStoreFileBatchObject|errorRetrieves a vector store file batch.
Return Type
post vector_stores/[string vectorStoreId]/file_batches/[string batchId]/cancel
function post vector_stores/[string vectorStoreId]/file_batches/[string batchId]/cancel(map<string|string[]> headers) returns VectorStoreFileBatchObject|errorCancel a vector store file batch. This attempts to cancel the processing of files in this batch as soon as possible.
Return Type
get vector_stores/[string vectorStoreId]/file_batches/[string batchId]/files
function get vector_stores/[string vectorStoreId]/file_batches/[string batchId]/files(map<string|string[]> headers, *ListFilesInVectorStoreBatchQueries queries) returns ListVectorStoreFilesResponse|errorReturns a list of vector store files in a batch.
Parameters
- queries *ListFilesInVectorStoreBatchQueries - Queries to be sent with the request
Return Type
get vector_stores/[string vectorStoreId]/files
function get vector_stores/[string vectorStoreId]/files(map<string|string[]> headers, *ListVectorStoreFilesQueries queries) returns ListVectorStoreFilesResponse|errorReturns a list of vector store files.
Parameters
- queries *ListVectorStoreFilesQueries - Queries to be sent with the request
Return Type
post vector_stores/[string vectorStoreId]/files
function post vector_stores/[string vectorStoreId]/files(CreateVectorStoreFileRequest payload, map<string|string[]> headers) returns VectorStoreFileObject|errorCreate a vector store file by attaching a File to a vector store.
Parameters
- payload CreateVectorStoreFileRequest -
Return Type
get vector_stores/[string vectorStoreId]/files/[string fileId]
function get vector_stores/[string vectorStoreId]/files/[string fileId](map<string|string[]> headers) returns VectorStoreFileObject|errorRetrieves a vector store file.
Return Type
post vector_stores/[string vectorStoreId]/files/[string fileId]
function post vector_stores/[string vectorStoreId]/files/[string fileId](UpdateVectorStoreFileAttributesRequest payload, map<string|string[]> headers) returns VectorStoreFileObject|errorUpdate attributes on a vector store file.
Parameters
- payload UpdateVectorStoreFileAttributesRequest -
Return Type
delete vector_stores/[string vectorStoreId]/files/[string fileId]
function delete vector_stores/[string vectorStoreId]/files/[string fileId](map<string|string[]> headers) returns DeleteVectorStoreFileResponse|errorDelete a vector store file. This will remove the file from the vector store but the file itself will not be deleted. To delete the file, use the delete file endpoint.
Return Type
get vector_stores/[string vectorStoreId]/files/[string fileId]/content
function get vector_stores/[string vectorStoreId]/files/[string fileId]/content(map<string|string[]> headers) returns VectorStoreFileContentResponse|errorRetrieve the parsed contents of a vector store file.
Return Type
post vector_stores/[string vectorStoreId]/search
function post vector_stores/[string vectorStoreId]/search(VectorStoreSearchRequest payload, map<string|string[]> headers) returns VectorStoreSearchResultsPage|errorSearch a vector store for relevant chunks based on a query and file attributes filter.
Parameters
- payload VectorStoreSearchRequest -
Return Type
Records
openai: AddUploadPartRequest
Fields
- data record { fileContent byte[], fileName string } - The chunk of bytes for this Part
openai: AdminApiKey
Represents an individual Admin API key in an org
Fields
- owner AdminApiKeyOwner -
- lastUsedAt int? - The Unix timestamp (in seconds) of when the API key was last used
- name string - The name of the API key
- createdAt int - The Unix timestamp (in seconds) of when the API key was created
- id string - The identifier, which can be referenced in API endpoints
- redactedValue string - The redacted value of the API key
- value? string - The value of the API key. Only shown on create
- 'object string - The object type, which is always
organization.admin_api_key
openai: AdminApiKeyOwner
Fields
- role? string - Always
owner
- name? string - The name of the user
- createdAt? int - The Unix timestamp (in seconds) of when the user was created
- id? string - The identifier, which can be referenced in API endpoints
- 'type? string - Always
user
- 'object? string - The object type, which is always organization.user
openai: AdminApiKeysListQueries
Represents the Queries record for the operation: admin-api-keys-list
Fields
- 'limit int(default 20) - Maximum number of keys to return.
- after? string? - Return keys with IDs that come after this ID in the pagination order.
- 'order "asc"|"desc" (default "asc") - Order results by creation time, ascending or descending.
openai: ApiKeyList
Fields
- firstId? string -
- data? AdminApiKey[] -
- lastId? string -
- hasMore? boolean -
- 'object? string -
openai: ApproximateLocation
Fields
- country? anydata -
- city? anydata -
- timezone? anydata -
- 'type "approximate" (default "approximate") - The type of location approximation. Always
approximate
- region? anydata -
openai: AssistantObject
Represents an assistant that can call the model and use tools
Fields
- instructions string? - The system instructions that the assistant uses. The maximum length is 256,000 characters
- toolResources? AssistantObjectToolResources? -
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- createdAt int - The Unix timestamp (in seconds) for when the assistant was created
- description string? - The description of the assistant. The maximum length is 512 characters
- tools AssistantObjectTools[](default []) - A list of tool enabled on the assistant. There can be a maximum of 128 tools per assistant. Tools can be of types
code_interpreter,file_search, orfunction
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering this or temperature but not both
- responseFormat? AssistantsApiResponseFormatOption -
- name string? - The name of the assistant. The maximum length is 256 characters
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic
- model string - ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them
- id string - The identifier, which can be referenced in API endpoints
- 'object "assistant" - The object type, which is always
assistant
openai: AssistantObjectToolResources
A set of resources that are used by the assistant's tools. The resources are specific to the type of tool. For example, the code_interpreter tool requires a list of file IDs, while the file_search tool requires a list of vector store IDs
Fields
- codeInterpreter? AssistantObjectToolResourcesCodeInterpreter -
- fileSearch? AssistantObjectToolResourcesFileSearch -
openai: AssistantObjectToolResourcesCodeInterpreter
Fields
openai: AssistantObjectToolResourcesFileSearch
Fields
- vectorStoreIds? string[] - The ID of the vector store attached to this assistant. There can be a maximum of 1 vector store attached to the assistant
openai: AssistantsNamedToolChoice
Specifies a tool the model should use. Use to force the model to call a specific tool
Fields
- 'function? AssistantsNamedToolChoiceFunction -
- 'type "function"|"code_interpreter"|"file_search" - The type of the tool. If type is
function, the function name must be set
openai: AssistantsNamedToolChoiceFunction
Fields
- name string - The name of the function to call
openai: AssistantToolsCode
Fields
- 'type "code_interpreter" - The type of tool being defined:
code_interpreter
openai: AssistantToolsFileSearch
Fields
- fileSearch? AssistantToolsFileSearchFileSearch -
- 'type "file_search" - The type of tool being defined:
file_search
openai: AssistantToolsFileSearchFileSearch
Overrides for the file search tool
Fields
- maxNumResults? int - The maximum number of results the file search tool should output. The default is 20 for
gpt-4*models and 5 forgpt-3.5-turbo. This number should be between 1 and 50 inclusive. Note that the file search tool may output fewer thanmax_num_resultsresults. See the file search tool documentation for more information
- rankingOptions? FileSearchRankingOptions -
openai: AssistantToolsFileSearchTypeOnly
Fields
- 'type "file_search" - The type of tool being defined:
file_search
openai: AssistantToolsFunction
Fields
- 'function FunctionObject -
- 'type "function" - The type of tool being defined:
function
openai: AuditLog
A log of a user action or configuration change within this organization
Fields
- rateLimitUpdated? AuditLogRateLimitupdated -
- userUpdated? AuditLogUserupdated -
- project? AuditLogProject - The project that the action was scoped to. Absent for actions not scoped to projects
- certificateDeleted? AuditLogCertificatedeleted -
- serviceAccountDeleted? AuditLogServiceAccountdeleted -
- 'type AuditLogEventType - The event type
- logoutFailed? AuditLogLoginfailed -
- certificateUpdated? AuditLogCertificatecreated -
- loginFailed? AuditLogLoginfailed -
- serviceAccountUpdated? AuditLogServiceAccountupdated -
- rateLimitDeleted? AuditLogRateLimitdeleted -
- id string - The ID of this log
- projectCreated? AuditLogProjectcreated -
- certificateCreated? AuditLogCertificatecreated -
- checkpointPermissionCreated? AuditLogCheckpointPermissioncreated -
- organizationUpdated? AuditLogOrganizationupdated -
- projectUpdated? AuditLogProjectupdated -
- projectArchived? AuditLogProjectarchived -
- userAdded? AuditLogUseradded -
- inviteAccepted? AuditLogInviteaccepted -
- inviteDeleted? AuditLogInviteaccepted -
- actor AuditLogActor - The actor who performed the audit logged action
- effectiveAt int - The Unix timestamp (in seconds) of the event
- checkpointPermissionDeleted? AuditLogCheckpointPermissiondeleted -
- inviteSent? AuditLogInvitesent -
- certificatesDeactivated? AuditLogCertificatesactivated -
- serviceAccountCreated? AuditLogServiceAccountcreated -
- apiKeyCreated? AuditLogApiKeycreated -
- userDeleted? AuditLogUserdeleted -
- apiKeyDeleted? AuditLogApiKeydeleted -
- certificatesActivated? AuditLogCertificatesactivated -
- apiKeyUpdated? AuditLogApiKeyupdated -
openai: AuditLogActor
The actor who performed the audit logged action
Fields
- apiKey? AuditLogActorApiKey -
- session? AuditLogActorSession - The session in which the audit logged action was performed
- 'type? "session"|"api_key" - The type of actor. Is either
sessionorapi_key
openai: AuditLogActorApiKey
The API Key used to perform the audit logged action
Fields
- serviceAccount? AuditLogActorServiceAccount -
- id? string - The tracking id of the API key
- 'type? "user"|"service_account" - The type of API key. Can be either
userorservice_account
- user? AuditLogActorUser - The user who performed the audit logged action
openai: AuditLogActorServiceAccount
The service account that performed the audit logged action
Fields
- id? string - The service account id
openai: AuditLogActorSession
The session in which the audit logged action was performed
Fields
- ipAddress? string - The IP address from which the action was performed
- user? AuditLogActorUser - The user who performed the audit logged action
openai: AuditLogActorUser
The user who performed the audit logged action
Fields
- id? string - The user id
- email? string - The user email
openai: AuditLogApiKeycreated
The details for events with this type
Fields
- data? AuditLogApiKeycreatedData - The payload used to create the API key
- id? string - The tracking ID of the API key
openai: AuditLogApiKeycreatedData
The payload used to create the API key
Fields
- scopes? string[] - A list of scopes allowed for the API key, e.g.
["api.model.request"]
openai: AuditLogApiKeydeleted
The details for events with this type
Fields
- id? string - The tracking ID of the API key
openai: AuditLogApiKeyupdated
The details for events with this type
Fields
- changesRequested? AuditLogApiKeyupdatedChangesRequested -
- id? string - The tracking ID of the API key
openai: AuditLogApiKeyupdatedChangesRequested
The payload used to update the API key
Fields
- scopes? string[] - A list of scopes allowed for the API key, e.g.
["api.model.request"]
openai: AuditLogCertificatecreated
The details for events with this type
Fields
- name? string - The name of the certificate
- id? string - The certificate ID
openai: AuditLogCertificatedeleted
The details for events with this type
Fields
- name? string - The name of the certificate
- certificate? string - The certificate content in PEM format
- id? string - The certificate ID
openai: AuditLogCertificatesactivated
The details for events with this type
Fields
- certificates? AuditLogCertificatesactivatedCertificates[] -
openai: AuditLogCertificatesactivatedCertificates
Fields
- name? string - The name of the certificate
- id? string - The certificate ID
openai: AuditLogCheckpointPermissioncreated
The project and fine-tuned model checkpoint that the checkpoint permission was created for
Fields
- data? AuditLogCheckpointPermissioncreatedData - The payload used to create the checkpoint permission
- id? string - The ID of the checkpoint permission
openai: AuditLogCheckpointPermissioncreatedData
The payload used to create the checkpoint permission
Fields
- projectId? string - The ID of the project that the checkpoint permission was created for
- fineTunedModelCheckpoint? string - The ID of the fine-tuned model checkpoint
openai: AuditLogCheckpointPermissiondeleted
The details for events with this type
Fields
- id? string - The ID of the checkpoint permission
openai: AuditLogInviteaccepted
The details for events with this type
Fields
- id? string - The ID of the invite
openai: AuditLogInvitesent
The details for events with this type
Fields
- data? AuditLogInvitesentData - The payload used to create the invite
- id? string - The ID of the invite
openai: AuditLogInvitesentData
The payload used to create the invite
Fields
- role? string - The role the email was invited to be. Is either
ownerormember
- email? string - The email invited to the organization
openai: AuditLogLoginfailed
The details for events with this type
Fields
- errorMessage? string - The error message of the failure
- errorCode? string - The error code of the failure
openai: AuditLogOrganizationupdated
The details for events with this type
Fields
- changesRequested? AuditLogOrganizationupdatedChangesRequested -
- id? string - The organization ID
openai: AuditLogOrganizationupdatedChangesRequested
The payload used to update the organization settings
Fields
- name? string - The organization name
- description? string - The organization description
- title? string - The organization title
openai: AuditLogOrganizationupdatedChangesRequestedSettings
Fields
- threadsUiVisibility? string - Visibility of the threads page which shows messages created with the Assistants API and Playground. One of
ANY_ROLE,OWNERS, orNONE
- usageDashboardVisibility? string - Visibility of the usage dashboard which shows activity and costs for your organization. One of
ANY_ROLEorOWNERS
openai: AuditLogProject
The project that the action was scoped to. Absent for actions not scoped to projects
Fields
- name? string - The project title
- id? string - The project ID
openai: AuditLogProjectarchived
The details for events with this type
Fields
- id? string - The project ID
openai: AuditLogProjectcreated
The details for events with this type
Fields
- data? AuditLogProjectcreatedData - The payload used to create the project
- id? string - The project ID
openai: AuditLogProjectcreatedData
The payload used to create the project
Fields
- name? string - The project name
- title? string - The title of the project as seen on the dashboard
openai: AuditLogProjectupdated
The details for events with this type
Fields
- changesRequested? AuditLogProjectupdatedChangesRequested -
- id? string - The project ID
openai: AuditLogProjectupdatedChangesRequested
The payload used to update the project
Fields
- title? string - The title of the project as seen on the dashboard
openai: AuditLogRateLimitdeleted
The details for events with this type
Fields
- id? string - The rate limit ID
openai: AuditLogRateLimitupdated
The details for events with this type
Fields
- changesRequested? AuditLogRateLimitupdatedChangesRequested -
- id? string - The rate limit ID
openai: AuditLogRateLimitupdatedChangesRequested
The payload used to update the rate limits
Fields
- batch1DayMaxInputTokens? int - The maximum batch input tokens per day. Only relevant for certain models
- maxTokensPer1Minute? int - The maximum tokens per minute
- maxImagesPer1Minute? int - The maximum images per minute. Only relevant for certain models
- maxAudioMegabytesPer1Minute? int - The maximum audio megabytes per minute. Only relevant for certain models
- maxRequestsPer1Minute? int - The maximum requests per minute
- maxRequestsPer1Day? int - The maximum requests per day. Only relevant for certain models
openai: AuditLogServiceAccountcreated
The details for events with this type
Fields
- data? AuditLogServiceAccountcreatedData - The payload used to create the service account
- id? string - The service account ID
openai: AuditLogServiceAccountcreatedData
The payload used to create the service account
Fields
- role? string - The role of the service account. Is either
ownerormember
openai: AuditLogServiceAccountdeleted
The details for events with this type
Fields
- id? string - The service account ID
openai: AuditLogServiceAccountupdated
The details for events with this type
Fields
- changesRequested? AuditLogServiceAccountupdatedChangesRequested -
- id? string - The service account ID
openai: AuditLogServiceAccountupdatedChangesRequested
The payload used to updated the service account
Fields
- role? string - The role of the service account. Is either
ownerormember
openai: AuditLogUseradded
The details for events with this type
Fields
- data? AuditLogUseraddedData - The payload used to add the user to the project
- id? string - The user ID
openai: AuditLogUseraddedData
The payload used to add the user to the project
Fields
- role? string - The role of the user. Is either
ownerormember
openai: AuditLogUserdeleted
The details for events with this type
Fields
- id? string - The user ID
openai: AuditLogUserupdated
The details for events with this type
Fields
- changesRequested? AuditLogUserupdatedChangesRequested -
- id? string - The project ID
openai: AuditLogUserupdatedChangesRequested
The payload used to update the user
Fields
- role? string - The role of the user. Is either
ownerormember
openai: AutoChunkingStrategyRequestParam
The default strategy. This strategy currently uses a max_chunk_size_tokens of 800 and chunk_overlap_tokens of 400
Fields
- 'type "auto" - Always
auto
openai: Batch
Fields
- cancelledAt? int - The Unix timestamp (in seconds) for when the batch was cancelled
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- requestCounts? BatchRequestCounts -
- inputFileId string - The ID of the input file for the batch
- outputFileId? string - The ID of the file containing the outputs of successfully executed requests
- errorFileId? string - The ID of the file containing the outputs of requests with errors
- createdAt int - The Unix timestamp (in seconds) for when the batch was created
- inProgressAt? int - The Unix timestamp (in seconds) for when the batch started processing
- expiredAt? int - The Unix timestamp (in seconds) for when the batch expired
- finalizingAt? int - The Unix timestamp (in seconds) for when the batch started finalizing
- completedAt? int - The Unix timestamp (in seconds) for when the batch was completed
- endpoint string - The OpenAI API endpoint used by the batch
- expiresAt? int - The Unix timestamp (in seconds) for when the batch will expire
- cancellingAt? int - The Unix timestamp (in seconds) for when the batch started cancelling
- completionWindow string - The time frame within which the batch should be processed
- id string -
- failedAt? int - The Unix timestamp (in seconds) for when the batch failed
- errors? BatchErrors -
- 'object "batch" - The object type, which is always
batch
- status "validating"|"failed"|"in_progress"|"finalizing"|"completed"|"expired"|"cancelling"|"cancelled" - The current status of the batch
openai: BatchErrors
Fields
- data? BatchErrorsData[] -
- 'object? string - The object type, which is always
list
openai: BatchErrorsData
Fields
- code? string - An error code identifying the error type
- param? string? - The name of the parameter that caused the error, if applicable
- line? int? - The line number of the input file where the error occurred, if applicable
- message? string - A human-readable message providing more details about the error
openai: BatchesBody
Fields
- endpoint "/v1/responses"|"/v1/chat/completions"|"/v1/embeddings"|"/v1/completions" - The endpoint to be used for all requests in the batch. Currently
/v1/responses,/v1/chat/completions,/v1/embeddings, and/v1/completionsare supported. Note that/v1/embeddingsbatches are also restricted to a maximum of 50,000 embedding inputs across all requests in the batch
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- inputFileId string - The ID of an uploaded file that contains requests for the new batch.
See upload file for how to upload a file.
Your input file must be formatted as a JSONL file, and must be uploaded with the purpose
batch. The file can contain up to 50,000 requests, and can be up to 200 MB in size
- completionWindow "24h" - The time frame within which the batch should be processed. Currently only
24his supported
openai: BatchRequestCounts
The request counts for different statuses within the batch
Fields
- total int - Total number of requests in the batch
- completed int - Number of requests that have been completed successfully
- failed int - Number of requests that have failed
openai: Certificate
Represents an individual certificate uploaded to the organization
Fields
- name string - The name of the certificate
- createdAt int - The Unix timestamp (in seconds) of when the certificate was uploaded
- active? boolean - Whether the certificate is currently active at the specified scope. Not returned when getting details for a specific certificate
- id string - The identifier, which can be referenced in API endpoints
- certificateDetails CertificateCertificateDetails -
- 'object "certificate"|"organization.certificate"|"organization.project.certificate" - The object type.
- If creating, updating, or getting a specific certificate, the object type is
certificate. - If listing, activating, or deactivating certificates for the organization, the object type is
organization.certificate. - If listing, activating, or deactivating certificates for a project, the object type is
organization.project.certificate
- If creating, updating, or getting a specific certificate, the object type is
openai: CertificateCertificateDetails
Fields
- expiresAt? int - The Unix timestamp (in seconds) of when the certificate expires
- content? string - The content of the certificate in PEM format
- validAt? int - The Unix timestamp (in seconds) of when the certificate becomes valid
openai: ChatCompletionDeleted
Fields
- deleted boolean - Whether the chat completion was deleted
- id string - The ID of the chat completion that was deleted
- 'object "chat.completion.deleted" - The type of object being deleted
openai: ChatCompletionFunctionCallOption
Specifying a particular function via {"name": "my_function"} forces the model to call that function
Fields
- name string - The name of the function to call
openai: ChatCompletionFunctions
Fields
- name string - The name of the function to be called. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64
- description? string - A description of what the function does, used by the model to choose when and how to call the function
- parameters? FunctionParameters - The parameters the functions accepts, described as a JSON Schema object. See the guide for examples, and the JSON Schema reference for documentation about the format.
Omitting
parametersdefines a function with an empty parameter list
openai: ChatCompletionList
An object representing a list of Chat Completions
Fields
- firstId string - The identifier of the first chat completion in the data array
- data CreateChatCompletionResponse[] - An array of chat completion objects
- lastId string - The identifier of the last chat completion in the data array
- hasMore boolean - Indicates whether there are more Chat Completions available
- 'object "list" (default "list") - The type of this object. It is always set to "list"
openai: ChatCompletionMessageList
An object representing a list of chat completion messages
Fields
- firstId string - The identifier of the first chat message in the data array
- data ChatCompletionMessageListData[] - An array of chat completion message objects
- lastId string - The identifier of the last chat message in the data array
- hasMore boolean - Indicates whether there are more chat messages available
- 'object "list" (default "list") - The type of this object. It is always set to "list"
openai: ChatCompletionMessageListData
Fields
- Fields Included from *ChatCompletionResponseMessage
- role "assistant"
- functionCall ChatCompletionResponseMessageFunctionCall
- refusal string|()
- annotations ChatCompletionResponseMessageAnnotations[]
- toolCalls ChatCompletionMessageToolCalls
- audio ChatCompletionResponseMessageAudio|()
- content string|()
- anydata...
- Fields Included from *DataAllOf2
- id string
- anydata...
openai: ChatCompletionMessageToolCall
Fields
- 'function ChatCompletionMessageToolCallFunction - The function that the model called
- id string - The ID of the tool call
- 'type "function" - The type of the tool. Currently, only
functionis supported
openai: ChatCompletionMessageToolCallFunction
The function that the model called
Fields
- name string - The name of the function to call
- arguments string - The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function
openai: ChatCompletionNamedToolChoice
Specifies a tool the model should use. Use to force the model to call a specific function
Fields
- 'function AssistantsNamedToolChoiceFunction -
- 'type "function" - The type of the tool. Currently, only
functionis supported
openai: ChatCompletionRequestAssistantMessage
Messages sent by the model in response to user messages
Fields
- role "assistant" - The role of the messages author, in this case
assistant
- functionCall? ChatCompletionRequestAssistantMessageFunctionCall? -
- refusal? string? - The refusal message by the assistant
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role
- toolCalls? ChatCompletionMessageToolCalls -
- audio? ChatCompletionRequestAssistantMessageAudio? - Data about a previous audio response from the model. Learn more
- content? string|ChatCompletionRequestAssistantMessageContentPart[]? - The contents of the assistant message. Required unless
tool_callsorfunction_callis specified
openai: ChatCompletionRequestAssistantMessageAudio
Data about a previous audio response from the model. Learn more
Fields
- id string - Unique identifier for a previous audio response from the model
openai: ChatCompletionRequestAssistantMessageFunctionCall
Deprecated and replaced by tool_calls. The name and arguments of a function that should be called, as generated by the model
Fields
- name string - The name of the function to call
- arguments string - The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function
Deprecated
openai: ChatCompletionRequestDeveloperMessage
Developer-provided instructions that the model should follow, regardless of
messages sent by the user. With o1 models and newer, developer messages
replace the previous system messages
Fields
- role "developer" - The role of the messages author, in this case
developer
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role
- content string|ChatCompletionRequestMessageContentPartText[] - The contents of the developer message
openai: ChatCompletionRequestFunctionMessage
Fields
- role "function" - The role of the messages author, in this case
function
- name string - The name of the function to call
- content string? - The contents of the function message
openai: ChatCompletionRequestMessageContentPartAudio
Learn about audio inputs
Fields
- 'type "input_audio" - The type of the content part. Always
input_audio
openai: ChatCompletionRequestMessageContentPartAudioInputAudio
Fields
- data string - Base64 encoded audio data
- format "wav"|"mp3" - The format of the encoded audio data. Currently supports "wav" and "mp3"
openai: ChatCompletionRequestMessageContentPartFile
Learn about file inputs for text generation
Fields
- 'type "file" - The type of the content part. Always
file
openai: ChatCompletionRequestMessageContentPartFileFile
Fields
- filename? string - The name of the file, used when passing the file to the model as a string
- fileId? string - The ID of an uploaded file to use as input
- fileData? string - The base64 encoded file data, used when passing the file to the model as a string
openai: ChatCompletionRequestMessageContentPartImage
Learn about image inputs
Fields
- 'type "image_url" - The type of the content part
openai: ChatCompletionRequestMessageContentPartImageImageUrl
Fields
- detail "auto"|"low"|"high" (default "auto") - Specifies the detail level of the image. Learn more in the Vision guide
- url string - Either a URL of the image or the base64 encoded image data
openai: ChatCompletionRequestMessageContentPartRefusal
Fields
- refusal string - The refusal message generated by the model
- 'type "refusal" - The type of the content part
openai: ChatCompletionRequestMessageContentPartText
Learn about text inputs
Fields
- text string - The text content
- 'type "text" - The type of the content part
openai: ChatCompletionRequestSystemMessage
Developer-provided instructions that the model should follow, regardless of
messages sent by the user. With o1 models and newer, use developer messages
for this purpose instead
Fields
- role "system" - The role of the messages author, in this case
system
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role
- content string|ChatCompletionRequestSystemMessageContentPart[] - The contents of the system message
openai: ChatCompletionRequestToolMessage
Fields
- role "tool" - The role of the messages author, in this case
tool
- toolCallId string - Tool call that this message is responding to
- content string|ChatCompletionRequestToolMessageContentPart[] - The contents of the tool message
openai: ChatCompletionRequestUserMessage
Messages sent by an end user, containing prompts or additional context information
Fields
- role "user" - The role of the messages author, in this case
user
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role
- content string|ChatCompletionRequestUserMessageContentPart[] - The contents of the user message
openai: ChatCompletionResponseMessage
A chat completion message generated by the model
Fields
- role "assistant" - The role of the author of this message
- functionCall? ChatCompletionResponseMessageFunctionCall -
- refusal string? - The refusal message generated by the model
- annotations? ChatCompletionResponseMessageAnnotations[] - Annotations for the message, when applicable, as when using the web search tool
- toolCalls? ChatCompletionMessageToolCalls -
- audio? ChatCompletionResponseMessageAudio? - If the audio output modality is requested, this object contains data about the audio response from the model. Learn more
- content string? - The contents of the message
openai: ChatCompletionResponseMessageAnnotations
A URL citation when using web search
Fields
- 'type "url_citation" - The type of the URL citation. Always
url_citation
- urlCitation ChatCompletionResponseMessageUrlCitation -
openai: ChatCompletionResponseMessageAudio
If the audio output modality is requested, this object contains data about the audio response from the model. Learn more
Fields
- expiresAt int - The Unix timestamp (in seconds) for when this audio response will no longer be accessible on the server for use in multi-turn conversations
- transcript string - Transcript of the audio generated by the model
- data string - Base64 encoded audio bytes generated by the model, in the format specified in the request
- id string - Unique identifier for this audio response
openai: ChatCompletionResponseMessageFunctionCall
Deprecated and replaced by tool_calls. The name and arguments of a function that should be called, as generated by the model
Fields
- name string - The name of the function to call
- arguments string - The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function
Deprecated
openai: ChatCompletionResponseMessageUrlCitation
A URL citation when using web search
Fields
- startIndex int - The index of the first character of the URL citation in the message
- endIndex int - The index of the last character of the URL citation in the message
- title string - The title of the web resource
- url string - The URL of the web resource
openai: ChatCompletionStreamOptions
Options for streaming response. Only set this when you set stream: true
Fields
- includeUsage? boolean - If set, an additional chunk will be streamed before the
data: [DONE]message. Theusagefield on this chunk shows the token usage statistics for the entire request, and thechoicesfield will always be an empty array. All other chunks will also include ausagefield, but with a null value. NOTE: If the stream is interrupted, you may not receive the final usage chunk which contains the total token usage for the request
openai: ChatCompletionTokenLogprob
Fields
- topLogprobs ChatCompletionTokenLogprobTopLogprobs[] - List of the most likely tokens and their log probability, at this token position. In rare cases, there may be fewer than the number of requested
top_logprobsreturned
- logprob decimal - The log probability of this token, if it is within the top 20 most likely tokens. Otherwise, the value
-9999.0is used to signify that the token is very unlikely
- bytes int[]? - A list of integers representing the UTF-8 bytes representation of the token. Useful in instances where characters are represented by multiple tokens and their byte representations must be combined to generate the correct text representation. Can be
nullif there is no bytes representation for the token
- token string - The token
openai: ChatCompletionTokenLogprobTopLogprobs
Fields
- logprob decimal - The log probability of this token, if it is within the top 20 most likely tokens. Otherwise, the value
-9999.0is used to signify that the token is very unlikely
- bytes int[]? - A list of integers representing the UTF-8 bytes representation of the token. Useful in instances where characters are represented by multiple tokens and their byte representations must be combined to generate the correct text representation. Can be
nullif there is no bytes representation for the token
- token string - The token
openai: ChatCompletionTool
Fields
- 'function FunctionObject -
- 'type "function" - The type of the tool. Currently, only
functionis supported
openai: Click
A click action
Fields
- x int - The x-coordinate where the click occurred
- y int - The y-coordinate where the click occurred
- 'type "click" (default "click") - Specifies the event type. For a click action, this property is
always set to
click
openai: ComparisonFilter
A filter used to compare a specified attribute key to a given value using a defined comparison operation
Fields
- 'type "eq"|"ne"|"gt"|"gte"|"lt"|"lte" (default "eq") - Specifies the comparison operator:
eq,ne,gt,gte,lt,lte.eq: equalsne: not equalgt: greater thangte: greater than or equallt: less thanlte: less than or equal
- 'key string - The key to compare against the value
openai: CompleteUploadRequest
Fields
- partIds string[] - The ordered list of Part IDs
- md5? string - The optional md5 checksum for the file contents to verify if the bytes uploaded matches what you expect
openai: CompletionscompletionIdBody
Fields
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
openai: CompletionUsage
Usage statistics for the completion request
Fields
- completionTokens int(default 0) - Number of tokens in the generated completion
- promptTokens int(default 0) - Number of tokens in the prompt
- completionTokensDetails? CompletionUsageCompletionTokensDetails -
- promptTokensDetails? CompletionUsagePromptTokensDetails -
- totalTokens int(default 0) - Total number of tokens used in the request (prompt + completion)
openai: CompletionUsageCompletionTokensDetails
Breakdown of tokens used in a completion
Fields
- acceptedPredictionTokens int(default 0) - When using Predicted Outputs, the number of tokens in the prediction that appeared in the completion
- audioTokens int(default 0) - Audio input tokens generated by the model
- reasoningTokens int(default 0) - Tokens generated by the model for reasoning
- rejectedPredictionTokens int(default 0) - When using Predicted Outputs, the number of tokens in the prediction that did not appear in the completion. However, like reasoning tokens, these tokens are still counted in the total completion tokens for purposes of billing, output, and context window limits
openai: CompletionUsagePromptTokensDetails
Breakdown of tokens used in the prompt
Fields
- audioTokens int(default 0) - Audio input tokens present in the prompt
- cachedTokens int(default 0) - Cached tokens present in the prompt
openai: CompoundFilter
Combine multiple filters using and or or
Fields
- filters CompoundFilterFilters[] - Array of filters to combine. Items can be
ComparisonFilterorCompoundFilter
- 'type "and"|"or" - Type of operation:
andoror
openai: ComputerCallOutputItemParam
The output of a computer tool call
Fields
- output ComputerScreenshotImage - A computer screenshot image used with the computer use tool
- acknowledgedSafetyChecks? anydata -
- id? anydata -
- 'type "computer_call_output" (default "computer_call_output") - The type of the computer tool call output. Always
computer_call_output
- callId string - The ID of the computer tool call that produced the output
- status? anydata -
openai: ComputerCallSafetyCheckParam
A pending safety check for the computer call
Fields
- code? anydata -
- id string - The ID of the pending safety check
- message? anydata -
openai: ComputerScreenshotImage
A computer screenshot image used with the computer use tool
Fields
- imageUrl? string - The URL of the screenshot image
- fileId? string - The identifier of an uploaded file that contains the screenshot
- 'type "computer_screenshot" (default "computer_screenshot") - Specifies the event type. For a computer screenshot, this property is
always set to
computer_screenshot
openai: ComputerToolCall
A tool call to a computer use tool. See the computer use guide for more information
Fields
- pendingSafetyChecks ComputerToolCallSafetyCheck[] - The pending safety checks for the computer call
- action ComputerAction -
- id string - The unique ID of the computer call
- 'type "computer_call" (default "computer_call") - The type of the computer call. Always
computer_call
- callId string - An identifier used when responding to the tool call with output
- status "in_progress"|"completed"|"incomplete" - The status of the item. One of
in_progress,completed, orincomplete. Populated when items are returned via API
openai: ComputerToolCallOutput
The output of a computer tool call
Fields
- output ComputerScreenshotImage - A computer screenshot image used with the computer use tool
- acknowledgedSafetyChecks? ComputerToolCallSafetyCheck[] - The safety checks reported by the API that have been acknowledged by the developer
- id? string - The ID of the computer tool call output
- 'type "computer_call_output" (default "computer_call_output") - The type of the computer tool call output. Always
computer_call_output
- callId string - The ID of the computer tool call that produced the output
- status? "in_progress"|"completed"|"incomplete" - The status of the message input. One of
in_progress,completed, orincomplete. Populated when input items are returned via API
openai: ComputerToolCallOutputResource
Fields
- Fields Included from *ComputerToolCallOutput
- output ComputerScreenshotImage
- acknowledgedSafetyChecks ComputerToolCallSafetyCheck[]
- id string
- type "computer_call_output"
- callId string
- status "in_progress"|"completed"|"incomplete"
- anydata...
- Fields Included from *ComputerToolCallOutputResourceAllOf2
- anydata...
openai: ComputerToolCallOutputResourceAllOf2
openai: ComputerToolCallSafetyCheck
A pending safety check for the computer call
Fields
- code string - The type of the pending safety check
- id string - The ID of the pending safety check
- message string - Details about the pending safety check
openai: ComputerUsePreviewTool
A tool that controls a virtual computer. Learn more about the computer tool
Fields
- environment "windows"|"mac"|"linux"|"ubuntu"|"browser" - The type of computer environment to control
- displayHeight int - The height of the computer display
- 'type "computer_use_preview" (default "computer_use_preview") - The type of the computer use tool. Always
computer_use_preview
- displayWidth int - The width of the computer display
openai: ConnectionConfig
Provides a set of configurations for controlling the behaviours when communicating with a remote HTTP endpoint.
Fields
- auth BearerTokenConfig - Configurations related to client authentication
- httpVersion HttpVersion(default http:HTTP_2_0) - The HTTP version understood by the client
- http1Settings ClientHttp1Settings(default {}) - Configurations related to HTTP/1.x protocol
- http2Settings ClientHttp2Settings(default {}) - Configurations related to HTTP/2 protocol
- timeout decimal(default 30) - The maximum time to wait (in seconds) for a response before closing the connection
- forwarded string(default "disable") - The choice of setting
forwarded/x-forwardedheader
- followRedirects? FollowRedirects - Configurations associated with Redirection
- poolConfig? PoolConfiguration - Configurations associated with request pooling
- cache CacheConfig(default {}) - HTTP caching related configurations
- compression Compression(default http:COMPRESSION_AUTO) - Specifies the way of handling compression (
accept-encoding) header
- circuitBreaker? CircuitBreakerConfig - Configurations associated with the behaviour of the Circuit Breaker
- retryConfig? RetryConfig - Configurations associated with retrying
- responseLimits ResponseLimitConfigs(default {}) - Configurations associated with inbound response size limits
- secureSocket? ClientSecureSocket - SSL/TLS-related options
- proxy? ProxyConfig - Proxy server related options
- socketConfig ClientSocketConfig(default {}) - Provides settings related to client socket configuration
- validation boolean(default true) - Enables the inbound payload validation functionality which provided by the constraint package. Enabled by default
- laxDataBinding boolean(default true) - Enables relaxed data binding on the client side. When enabled,
nilvalues are treated as optional, and absent fields are handled asnilabletypes. Enabled by default.
openai: Coordinate
An x/y coordinate pair, e.g. { x: 100, y: 200 }
Fields
- x int - The x-coordinate
- y int - The y-coordinate
openai: CostsResult
The aggregated costs details of the specific time bucket
Fields
- amount? CostsResultAmount - The monetary value in its associated currency
- lineItem? string? - When
group_by=line_item, this field provides the line item of the grouped costs result
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped costs result
- 'object "organization.costs.result" -
openai: CostsResultAmount
The monetary value in its associated currency
Fields
- currency? string - Lowercase ISO-4217 currency e.g. "usd"
- value? decimal - The numeric value of the cost
openai: CreateAssistantRequest
Fields
- reasoningEffort? ReasoningEffort? -
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering this or temperature but not both
- instructions? string? - The system instructions that the assistant uses. The maximum length is 256,000 characters
- toolResources? CreateAssistantRequestToolResources? -
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- responseFormat? AssistantsApiResponseFormatOption -
- name? string? - The name of the assistant. The maximum length is 256 characters
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic
- description? string? - The description of the assistant. The maximum length is 512 characters
- model string|AssistantSupportedModels - ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them
- tools AssistantObjectTools[](default []) - A list of tool enabled on the assistant. There can be a maximum of 128 tools per assistant. Tools can be of types
code_interpreter,file_search, orfunction
openai: CreateAssistantRequestToolResources
A set of resources that are used by the assistant's tools. The resources are specific to the type of tool. For example, the code_interpreter tool requires a list of file IDs, while the file_search tool requires a list of vector store IDs
Fields
- codeInterpreter? CreateAssistantRequestToolResourcesCodeInterpreter -
- fileSearch? CreateAssistantRequestToolResourcesFileSearch -
openai: CreateAssistantRequestToolResourcesCodeInterpreter
Fields
openai: CreateChatCompletionRequest
Fields
- Fields Included from *CreateChatCompletionRequestAllOf2
- reasoningEffort "high"|()|"low"|"medium"
- topLogprobs int|()
- logitBias record { int... }|()
- seed int|()
- functions ChatCompletionFunctions[]
- functionCall ChatCompletionFunctionCallOption|"none"|"auto"
- presencePenalty decimal|()
- tools ChatCompletionTool[]
- webSearchOptions WebSearch
- logprobs boolean|()
- maxCompletionTokens int|()
- modalities "text"|"audio"[]|()
- frequencyPenalty decimal|()
- responseFormat ResponseFormatText|ResponseFormatJsonSchema|ResponseFormatJsonObject
- stream boolean|()
- toolChoice ChatCompletionToolChoiceOption
- model ModelIdsShared
- audio CreateChatCompletionRequestAudio|()
- maxTokens int|()
- store boolean|()
- n int|()
- stop string|()|StopConfigurationStopConfigurationOneOf12
- parallelToolCalls ParallelToolCalls
- prediction PredictionContent|()
- messages ChatCompletionRequestMessage[]
- streamOptions ChatCompletionStreamOptions|()
- anydata...
openai: CreateChatCompletionRequestAllOf2
Fields
- reasoningEffort? ReasoningEffort? -
- topLogprobs? int? - An integer between 0 and 20 specifying the number of most likely tokens to
return at each token position, each with an associated log probability.
logprobsmust be set totrueif this parameter is used
- logitBias? record { int... }? - Modify the likelihood of specified tokens appearing in the completion. Accepts a JSON object that maps tokens (specified by their token ID in the tokenizer) to an associated bias value from -100 to 100. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token
- seed? int? - This feature is in Beta.
If specified, our system will make a best effort to sample deterministically, such that repeated requests with the same
seedand parameters should return the same result. Determinism is not guaranteed, and you should refer to thesystem_fingerprintresponse parameter to monitor changes in the backend
- functions? ChatCompletionFunctions[] - Deprecated in favor of
tools. A list of functions the model may generate JSON inputs for
- functionCall? "none"|"auto"|ChatCompletionFunctionCallOption - Deprecated in favor of
tool_choice. Controls which (if any) function is called by the model.nonemeans the model will not call a function and instead generates a message.automeans the model can pick between generating a message or calling a function. Specifying a particular function via{"name": "my_function"}forces the model to call that function.noneis the default when no functions are present.autois the default if functions are present
- presencePenalty decimal?(default 0) - Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics
- tools? ChatCompletionTool[] - A list of tools the model may call. Currently, only functions are supported as a tool. Use this to provide a list of functions the model may generate JSON inputs for. A max of 128 functions are supported
- webSearchOptions? WebSearch -
- logprobs boolean?(default false) - Whether to return log probabilities of the output tokens or not. If true,
returns the log probabilities of each output token returned in the
contentofmessage
- maxCompletionTokens? int? - An upper bound for the number of tokens that can be generated for a completion, including visible output tokens and reasoning tokens
- modalities? ResponseModalities? - Output types that you would like the model to generate.
Most models are capable of generating text, which is the default:
["text"]Thegpt-4o-audio-previewmodel can also be used to generate audio. To request that this model generate both text and audio responses, you can use:["text", "audio"]
- frequencyPenalty decimal?(default 0) - Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim
- responseFormat? ResponseFormatText|ResponseFormatJsonSchema|ResponseFormatJsonObject - An object specifying the format that the model must output.
Setting to
{ "type": "json_schema", "json_schema": {...} }enables Structured Outputs which ensures the model will match your supplied JSON schema. Learn more in the Structured Outputs guide. Setting to{ "type": "json_object" }enables the older JSON mode, which ensures the message the model generates is valid JSON. Usingjson_schemais preferred for models that support it
- 'stream boolean?(default false) - If set to true, the model response data will be streamed to the client as it is generated using server-sent events. See the Streaming section below for more information, along with the streaming responses guide for more information on how to handle the streaming events
- toolChoice? ChatCompletionToolChoiceOption -
- model ModelIdsShared -
- audio? CreateChatCompletionRequestAudio? - Parameters for audio output. Required when audio output is requested with
modalities: ["audio"]. Learn more
- maxTokens? int? - The maximum number of tokens that can be generated in the
chat completion. This value can be used to control
costs for text generated via API.
This value is now deprecated in favor of
max_completion_tokens, and is not compatible with o-series models
- store boolean?(default false) - Whether or not to store the output of this chat completion request for use in our model distillation or evals products
- n int?(default 1) - How many chat completion choices to generate for each input message. Note that you will be charged based on the number of generated tokens across all of the choices. Keep
nas1to minimize costs
- stop? StopConfiguration? - Not supported with latest reasoning models
o3ando4-mini. Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence
- parallelToolCalls? ParallelToolCalls -
- prediction? PredictionContent? - Configuration for a Predicted Output, which can greatly improve response times when large parts of the model response are known ahead of time. This is most common when you are regenerating a file with only minor changes to most of the content
- messages ChatCompletionRequestMessage[] - A list of messages comprising the conversation so far. Depending on the model you use, different message types (modalities) are supported, like text, images, and audio
- streamOptions? ChatCompletionStreamOptions? -
openai: CreateChatCompletionRequestAudio
Parameters for audio output. Required when audio output is requested with
modalities: ["audio"]. Learn more
Fields
- voice VoiceIdsShared -
- format "wav"|"aac"|"mp3"|"flac"|"opus"|"pcm16" - Specifies the output audio format. Must be one of
wav,mp3,flac,opus, orpcm16
openai: CreateChatCompletionResponse
Represents a chat completion response returned by model, based on the provided input
Fields
- created int - The Unix timestamp (in seconds) of when the chat completion was created
- usage? CompletionUsage - Usage statistics for the completion request
- model string - The model used for the chat completion
- serviceTier? ServiceTier? -
- id string - A unique identifier for the chat completion
- choices CreateChatCompletionResponseChoices[] - A list of chat completion choices. Can be more than one if
nis greater than 1
- systemFingerprint? string - This fingerprint represents the backend configuration that the model runs with.
Can be used in conjunction with the
seedrequest parameter to understand when backend changes have been made that might impact determinism
- 'object "chat.completion" - The object type, which is always
chat.completion
openai: CreateChatCompletionResponseChoices
Fields
- finishReason "stop"|"length"|"tool_calls"|"content_filter"|"function_call" - The reason the model stopped generating tokens. This will be
stopif the model hit a natural stop point or a provided stop sequence,lengthif the maximum number of tokens specified in the request was reached,content_filterif content was omitted due to a flag from our content filters,tool_callsif the model called a tool, orfunction_call(deprecated) if the model called a function
- index int - The index of the choice in the list of choices
- message ChatCompletionResponseMessage - A chat completion message generated by the model
- logprobs CreateChatCompletionResponseLogprobs? - Log probability information for the choice
openai: CreateChatCompletionResponseLogprobs
Log probability information for the choice
Fields
- refusal ChatCompletionTokenLogprob[]? - A list of message refusal tokens with log probability information
- content ChatCompletionTokenLogprob[]? - A list of message content tokens with log probability information
openai: CreateCompletionRequest
Fields
- logitBias? record { int... }? - Modify the likelihood of specified tokens appearing in the completion.
Accepts a JSON object that maps tokens (specified by their token ID in the GPT tokenizer) to an associated bias value from -100 to 100. You can use this tokenizer tool to convert text to token IDs. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
As an example, you can pass
{"50256": -100}to prevent the <|endoftext|> token from being generated
- seed? int? - If specified, our system will make a best effort to sample deterministically, such that repeated requests with the same
seedand parameters should return the same result. Determinism is not guaranteed, and you should refer to thesystem_fingerprintresponse parameter to monitor changes in the backend
- maxTokens int?(default 16) - The maximum number of tokens that can be generated in the completion.
The token count of your prompt plus
max_tokenscannot exceed the model's context length. Example Python code for counting tokens
- presencePenalty decimal?(default 0) - Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics. See more information about frequency and presence penalties.
- echo boolean?(default false) - Echo back the prompt in addition to the completion
- suffix? string? - The suffix that comes after a completion of inserted text.
This parameter is only supported for
gpt-3.5-turbo-instruct
- n int?(default 1) - How many completions to generate for each prompt.
Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings for
max_tokensandstop
- logprobs? int? - Include the log probabilities on the
logprobsmost likely output tokens, as well the chosen tokens. For example, iflogprobsis 5, the API will return a list of the 5 most likely tokens. The API will always return thelogprobof the sampled token, so there may be up tologprobs+1elements in the response. The maximum value forlogprobsis 5
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
We generally recommend altering this or
temperaturebut not both
- frequencyPenalty decimal?(default 0) - Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim. See more information about frequency and presence penalties.
- bestOf int?(default 1) - Generates
best_ofcompletions server-side and returns the "best" (the one with the highest log probability per token). Results cannot be streamed. When used withn,best_ofcontrols the number of candidate completions andnspecifies how many to return –best_ofmust be greater thann. Note: Because this parameter generates many completions, it can quickly consume your token quota. Use carefully and ensure that you have reasonable settings formax_tokensandstop
- stop? StopConfiguration? - Not supported with latest reasoning models
o3ando4-mini. Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence
- 'stream boolean?(default false) - Whether to stream back partial progress. If set, tokens will be sent as data-only server-sent events as they become available, with the stream terminated by a
data: [DONE]message. Example Python code
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
We generally recommend altering this or
top_pbut not both
- model string|"gpt-3.5-turbo-instruct"|"davinci-002"|"babbage-002" - ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them
- streamOptions? ChatCompletionStreamOptions? -
- prompt string|string[]|int[]|PromptItemsArray[]?(default "<|endoftext|>") - The prompt(s) to generate completions for, encoded as a string, array of strings, array of tokens, or array of token arrays. Note that <|endoftext|> is the document separator that the model sees during training, so if a prompt is not specified the model will generate as if from the beginning of a new document
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more
openai: CreateCompletionResponse
Represents a completion response from the API. Note: both the streamed and non-streamed response objects share the same shape (unlike the chat endpoint)
Fields
- created int - The Unix timestamp (in seconds) of when the completion was created
- usage? CompletionUsage - Usage statistics for the completion request
- model string - The model used for completion
- id string - A unique identifier for the completion
- choices CreateCompletionResponseChoices[] - The list of completion choices the model generated for the input prompt
- systemFingerprint? string - This fingerprint represents the backend configuration that the model runs with.
Can be used in conjunction with the
seedrequest parameter to understand when backend changes have been made that might impact determinism
- 'object "text_completion" - The object type, which is always "text_completion"
openai: CreateCompletionResponseChoices
Fields
- finishReason "stop"|"length"|"content_filter" - The reason the model stopped generating tokens. This will be
stopif the model hit a natural stop point or a provided stop sequence,lengthif the maximum number of tokens specified in the request was reached, orcontent_filterif content was omitted due to a flag from our content filters
- index int -
- text string -
- logprobs CreateCompletionResponseLogprobs? -
openai: CreateCompletionResponseLogprobs
Fields
- topLogprobs? record {||}[] -
- tokenLogprobs? decimal[] -
- tokens? string[] -
- textOffset? int[] -
openai: CreateEmbeddingRequest
Fields
- input string|string[]|int[]|InputItemsArray[] - Input text to embed, encoded as a string or array of tokens. To embed multiple inputs in a single request, pass an array of strings or array of token arrays. The input must not exceed the max input tokens for the model (8192 tokens for
text-embedding-ada-002), cannot be an empty string, and any array must be 2048 dimensions or less. Example Python code for counting tokens. Some models may also impose a limit on total number of tokens summed across inputs
- encodingFormat "float"|"base64" (default "float") - The format to return the embeddings in. Can be either
floatorbase64
- model string|"text-embedding-ada-002"|"text-embedding-3-small"|"text-embedding-3-large" - ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more
- dimensions? int - The number of dimensions the resulting output embeddings should have. Only supported in
text-embedding-3and later models
openai: CreateEmbeddingResponse
Fields
- data Embedding[] - The list of embeddings generated by the model
- usage CreateEmbeddingResponseUsage - The usage information for the request
- model string - The name of the model used to generate the embedding
- 'object "list" - The object type, which is always "list"
openai: CreateEmbeddingResponseUsage
The usage information for the request
Fields
- promptTokens int - The number of tokens used by the prompt
- totalTokens int - The total number of tokens used by the request
openai: CreateEvalCompletionsRunDataSource
A CompletionsRunDataSource object describing a model sampling configuration
Fields
- inputMessages? record { 'type "template" , template (EasyInputMessage|EvalItem)[] }|record { 'type "item_reference" , item_reference string } -
- model? string - The name of the model to use for generating completions (e.g. "o3-mini")
- 'type "completions" (default "completions") - The type of run data source. Always
completions
- samplingParams? CreateEvalCompletionsRunDataSourceSamplingParams -
openai: CreateEvalCompletionsRunDataSourceSamplingParams
Fields
- topP decimal(default 1) - An alternative to temperature for nucleus sampling; 1.0 includes all tokens
- maxCompletionTokens? int - The maximum number of tokens in the generated output
- seed int(default 42) - A seed value to initialize the randomness, during sampling
- temperature decimal(default 1) - A higher temperature increases randomness in the outputs
openai: CreateEvalCustomDataSourceConfig
A CustomDataSourceConfig object that defines the schema for the data source used for the evaluation runs. This schema is used to define the shape of the data that will be:
- Used to define your testing criteria and
- What data is required when creating a run
Fields
- itemSchema record {} - The json schema for each row in the data source
- includeSampleSchema boolean(default false) - Whether the eval should expect you to populate the sample namespace (ie, by generating responses off of your data source)
- 'type "custom" (default "custom") - The type of data source. Always
custom
openai: CreateEvalJsonlRunDataSource
A JsonlRunDataSource object with that specifies a JSONL file that matches the eval
Fields
- 'type "jsonl" (default "jsonl") - The type of data source. Always
jsonl
openai: CreateEvalLabelModelGrader
A LabelModelGrader object which uses a model to assign labels to each item in the evaluation
Fields
- input CreateEvalItem[] - A list of chat messages forming the prompt or context. May include variable references to the "item" namespace, ie {{item.name}}
- name string - The name of the grader
- model string - The model to use for the evaluation. Must support structured outputs
- passingLabels string[] - The labels that indicate a passing result. Must be a subset of labels
- 'type "label_model" - The object type, which is always
label_model
- labels string[] - The labels to classify to each item in the evaluation
openai: CreateEvalLogsDataSourceConfig
A data source config which specifies the metadata property of your stored completions query.
This is usually metadata like usecase=chatbot or prompt-version=v2, etc
Fields
- metadata? record {} - Metadata filters for the logs data source
- 'type "logs" (default "logs") - The type of data source. Always
logs
openai: CreateEvalRequest
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- name? string - The name of the evaluation
- testingCriteria CreateEvalRequestTestingCriteria[] - A list of graders for all eval runs in this group
- dataSourceConfig CreateEvalCustomDataSourceConfig|CreateEvalLogsDataSourceConfig - The configuration for the data source used for the evaluation runs
openai: CreateEvalResponsesRunDataSource
A ResponsesRunDataSource object describing a model sampling configuration
Fields
- model? string - The name of the model to use for generating completions (e.g. "o3-mini")
- 'type "completions" (default "completions") - The type of run data source. Always
completions
- samplingParams? CreateEvalCompletionsRunDataSourceSamplingParams -
openai: CreateEvalRunRequest
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- name? string - The name of the run
- dataSource CreateEvalJsonlRunDataSource|CreateEvalCompletionsRunDataSource|CreateEvalResponsesRunDataSource - Details about the run's data source
openai: CreateFileRequest
Fields
- file record { fileContent byte[], fileName string } - The File object (not file name) to be uploaded
- purpose "assistants"|"batch"|"fine-tune"|"vision"|"user_data"|"evals" - The intended purpose of the uploaded file. One of: -
assistants: Used in the Assistants API -batch: Used in the Batch API -fine-tune: Used for fine-tuning -vision: Images used for vision fine-tuning -user_data: Flexible file type for any purpose -evals: Used for eval data sets
openai: CreateFineTuningCheckpointPermissionRequest
Fields
- projectIds string[] - The project identifiers to grant access to
openai: CreateFineTuningJobRequest
Fields
- trainingFile string - The ID of an uploaded file that contains training data.
See upload file for how to upload a file.
Your dataset must be formatted as a JSONL file. Additionally, you must upload your file with the purpose
fine-tune. The contents of the file should differ depending on if the model uses the chat, completions format, or if the fine-tuning method uses the preference format. See the fine-tuning guide for more details
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- seed? int? - The seed controls the reproducibility of the job. Passing in the same seed and job parameters should produce the same results, but may differ in rare cases. If a seed is not specified, one will be generated for you
- method? FineTuneMethod - The method used for fine-tuning
- validationFile? string? - The ID of an uploaded file that contains validation data.
If you provide this file, the data is used to generate validation
metrics periodically during fine-tuning. These metrics can be viewed in
the fine-tuning results file.
The same data should not be present in both train and validation files.
Your dataset must be formatted as a JSONL file. You must upload your file with the purpose
fine-tune. See the fine-tuning guide for more details
- hyperparameters? CreateFineTuningJobRequestHyperparameters - The hyperparameters used for the fine-tuning job.
This value is now deprecated in favor of
method, and should be passed in under themethodparameter
- model string|"babbage-002"|"davinci-002"|"gpt-3.5-turbo"|"gpt-4o-mini" - The name of the model to fine-tune. You can select one of the supported models
- suffix? string? - A string of up to 64 characters that will be added to your fine-tuned model name.
For example, a
suffixof "custom-model-name" would produce a model name likeft:gpt-4o-mini:openai:custom-model-name:7p4lURel
- integrations? CreateFineTuningJobRequestIntegrations[]? - A list of integrations to enable for your fine-tuning job
openai: CreateFineTuningJobRequestHyperparameters
The hyperparameters used for the fine-tuning job.
This value is now deprecated in favor of method, and should be passed in under the method parameter
Fields
- batchSize "auto"|int(default "auto") - Number of examples in each batch. A larger batch size means that model parameters are updated less frequently, but with lower variance
- nEpochs "auto"|int(default "auto") - The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset
- learningRateMultiplier "auto"|decimal(default "auto") - Scaling factor for the learning rate. A smaller learning rate may be useful to avoid overfitting
Deprecated
openai: CreateFineTuningJobRequestIntegrations
Fields
- wandb CreateFineTuningJobRequestWandb - The settings for your integration with Weights and Biases. This payload specifies the project that metrics will be sent to. Optionally, you can set an explicit display name for your run, add tags to your run, and set a default entity (team, username, etc) to be associated with your run
- 'type "wandb" - The type of integration to enable. Currently, only "wandb" (Weights and Biases) is supported
openai: CreateFineTuningJobRequestWandb
The settings for your integration with Weights and Biases. This payload specifies the project that metrics will be sent to. Optionally, you can set an explicit display name for your run, add tags to your run, and set a default entity (team, username, etc) to be associated with your run
Fields
- name? string? - A display name to set for the run. If not set, we will use the Job ID as the name
- project string - The name of the project that the new run will be created under
- entity? string? - The entity to use for the run. This allows you to set the team or username of the WandB user that you would like associated with the run. If not set, the default entity for the registered WandB API key is used
openai: CreateImageEditRequest
Fields
- image record { fileContent byte[], fileName string }|record { fileContent byte[], fileName string }[] - The image(s) to edit. Must be a supported image file or an array of images.
For
gpt-image-1, each image should be apng,webp, orjpgfile less than 25MB. You can provide up to 16 images. Fordall-e-2, you can only provide one image, and it should be a squarepngfile less than 4MB
- responseFormat "url"|"b64_json"?(default "url") - The format in which the generated images are returned. Must be one of
urlorb64_json. URLs are only valid for 60 minutes after the image has been generated. This parameter is only supported fordall-e-2, asgpt-image-1will always return base64-encoded images
- size "256x256"|"512x512"|"1024x1024"|"1536x1024"|"1024x1536"|"auto"?(default "1024x1024") - The size of the generated images. Must be one of
1024x1024,1536x1024(landscape),1024x1536(portrait), orauto(default value) forgpt-image-1, and one of256x256,512x512, or1024x1024fordall-e-2
- model string|"dall-e-2"|"gpt-image-1"?(default "dall-e-2") - The model to use for image generation. Only
dall-e-2andgpt-image-1are supported. Defaults todall-e-2unless a parameter specific togpt-image-1is used
- prompt string - A text description of the desired image(s). The maximum length is 1000 characters for
dall-e-2, and 32000 characters forgpt-image-1
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more
- n int?(default 1) - The number of images to generate. Must be between 1 and 10
- mask? record { fileContent byte[], fileName string } - An additional image whose fully transparent areas (e.g. where alpha is zero) indicate where
imageshould be edited. If there are multiple images provided, the mask will be applied on the first image. Must be a valid PNG file, less than 4MB, and have the same dimensions asimage
- quality "standard"|"low"|"medium"|"high"|"auto"?(default "auto") - The quality of the image that will be generated.
high,mediumandloware only supported forgpt-image-1.dall-e-2only supportsstandardquality. Defaults toauto
openai: CreateImageRequest
Fields
- responseFormat "url"|"b64_json"?(default "url") - The format in which generated images with
dall-e-2anddall-e-3are returned. Must be one ofurlorb64_json. URLs are only valid for 60 minutes after the image has been generated. This parameter isn't supported forgpt-image-1which will always return base64-encoded images
- outputFormat "png"|"jpeg"|"webp"?(default "png") - The format in which the generated images are returned. This parameter is only supported for
gpt-image-1. Must be one ofpng,jpeg, orwebp
- size "auto"|"1024x1024"|"1536x1024"|"1024x1536"|"256x256"|"512x512"|"1792x1024"|"1024x1792"?(default "auto") - The size of the generated images. Must be one of
1024x1024,1536x1024(landscape),1024x1536(portrait), orauto(default value) forgpt-image-1, one of256x256,512x512, or1024x1024fordall-e-2, and one of1024x1024,1792x1024, or1024x1792fordall-e-3
- outputCompression int?(default 100) - The compression level (0-100%) for the generated images. This parameter is only supported for
gpt-image-1with thewebporjpegoutput formats, and defaults to 100
- background "transparent"|"opaque"|"auto"?(default "auto") - Allows to set transparency for the background of the generated image(s).
This parameter is only supported for
gpt-image-1. Must be one oftransparent,opaqueorauto(default value). Whenautois used, the model will automatically determine the best background for the image. Iftransparent, the output format needs to support transparency, so it should be set to eitherpng(default value) orwebp
- moderation "low"|"auto"?(default "auto") - Control the content-moderation level for images generated by
gpt-image-1. Must be eitherlowfor less restrictive filtering orauto(default value)
- model string|"dall-e-2"|"dall-e-3"|"gpt-image-1"?(default "dall-e-2") - The model to use for image generation. One of
dall-e-2,dall-e-3, orgpt-image-1. Defaults todall-e-2unless a parameter specific togpt-image-1is used
- style "vivid"|"natural"?(default "vivid") - The style of the generated images. This parameter is only supported for
dall-e-3. Must be one ofvividornatural. Vivid causes the model to lean towards generating hyper-real and dramatic images. Natural causes the model to produce more natural, less hyper-real looking images
- prompt string - A text description of the desired image(s). The maximum length is 32000 characters for
gpt-image-1, 1000 characters fordall-e-2and 4000 characters fordall-e-3
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more
- n int?(default 1) - The number of images to generate. Must be between 1 and 10. For
dall-e-3, onlyn=1is supported
- quality "standard"|"hd"|"low"|"medium"|"high"|"auto"?(default "auto") - The quality of the image that will be generated.
auto(default value) will automatically select the best quality for the given model.high,mediumandloware supported forgpt-image-1.hdandstandardare supported fordall-e-3.standardis the only option fordall-e-2
openai: CreateImageVariationRequest
Fields
- image record { fileContent byte[], fileName string } - The image to use as the basis for the variation(s). Must be a valid PNG file, less than 4MB, and square
- responseFormat "url"|"b64_json"?(default "url") - The format in which the generated images are returned. Must be one of
urlorb64_json. URLs are only valid for 60 minutes after the image has been generated
- size "256x256"|"512x512"|"1024x1024"?(default "1024x1024") - The size of the generated images. Must be one of
256x256,512x512, or1024x1024
- model string|"dall-e-2"?(default "dall-e-2") - The model to use for image generation. Only
dall-e-2is supported at this time
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more
- n int?(default 1) - The number of images to generate. Must be between 1 and 10
openai: CreateMessageRequest
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- role "user"|"assistant" - The role of the entity that is creating the message. Allowed values include:
user: Indicates the message is sent by an actual user and should be used in most cases to represent user-generated messages.assistant: Indicates the message is generated by the assistant. Use this value to insert messages from the assistant into the conversation
- attachments? CreateMessageRequestAttachments[]? - A list of files attached to the message, and the tools they should be added to
openai: CreateMessageRequestAttachments
Fields
- fileId? string - The ID of the file to attach to the message
- tools? CreateMessageRequestTools[] - The tools to add this file to
openai: CreateModerationRequest
Fields
- model string|"omni-moderation-latest"|"omni-moderation-2024-09-26"|"text-moderation-latest"|"text-moderation-stable" (default "omni-moderation-latest") - The content moderation model you would like to use. Learn more in the moderation guide, and learn about available models here
openai: CreateModerationResponse
Represents if a given text input is potentially harmful
Fields
- model string - The model used to generate the moderation results
- id string - The unique identifier for the moderation request
- results CreateModerationResponseResults[] - A list of moderation objects
openai: CreateModerationResponseCategories
A list of the categories, and whether they are flagged or not
Fields
- illicitViolent boolean? - Content that includes instructions or advice that facilitate the planning or execution of wrongdoing that also includes violence, or that gives advice or instruction on the procurement of any weapon
- selfHarmInstructions boolean - Content that encourages performing acts of self-harm, such as suicide, cutting, and eating disorders, or that gives instructions or advice on how to commit such acts
- harassment boolean - Content that expresses, incites, or promotes harassing language towards any target
- violenceGraphic boolean - Content that depicts death, violence, or physical injury in graphic detail
- illicit boolean? - Content that includes instructions or advice that facilitate the planning or execution of wrongdoing, or that gives advice or instruction on how to commit illicit acts. For example, "how to shoplift" would fit this category
- selfHarmIntent boolean - Content where the speaker expresses that they are engaging or intend to engage in acts of self-harm, such as suicide, cutting, and eating disorders
- hateThreatening boolean - Hateful content that also includes violence or serious harm towards the targeted group based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste
- sexualMinors boolean - Sexual content that includes an individual who is under 18 years old
- harassmentThreatening boolean - Harassment content that also includes violence or serious harm towards any target
- hate boolean - Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. Hateful content aimed at non-protected groups (e.g., chess players) is harassment
- selfHarm boolean - Content that promotes, encourages, or depicts acts of self-harm, such as suicide, cutting, and eating disorders
- sexual boolean - Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness)
- violence boolean - Content that depicts death, violence, or physical injury
openai: CreateModerationResponseCategoryAppliedInputTypes
A list of the categories along with the input type(s) that the score applies to
Fields
- illicitViolent ("text")[] - The applied input type(s) for the category 'illicit/violent'
- selfHarmInstructions ("text"|"image")[] - The applied input type(s) for the category 'self-harm/instructions'
- harassment ("text")[] - The applied input type(s) for the category 'harassment'
- violenceGraphic ("text"|"image")[] - The applied input type(s) for the category 'violence/graphic'
- illicit ("text")[] - The applied input type(s) for the category 'illicit'
- selfHarmIntent ("text"|"image")[] - The applied input type(s) for the category 'self-harm/intent'
- hateThreatening ("text")[] - The applied input type(s) for the category 'hate/threatening'
- sexualMinors ("text")[] - The applied input type(s) for the category 'sexual/minors'
- harassmentThreatening ("text")[] - The applied input type(s) for the category 'harassment/threatening'
- hate ("text")[] - The applied input type(s) for the category 'hate'
- selfHarm ("text"|"image")[] - The applied input type(s) for the category 'self-harm'
- sexual ("text"|"image")[] - The applied input type(s) for the category 'sexual'
- violence ("text"|"image")[] - The applied input type(s) for the category 'violence'
openai: CreateModerationResponseCategoryScores
A list of the categories along with their scores as predicted by model
Fields
- illicitViolent decimal - The score for the category 'illicit/violent'
- selfHarmInstructions decimal - The score for the category 'self-harm/instructions'
- harassment decimal - The score for the category 'harassment'
- violenceGraphic decimal - The score for the category 'violence/graphic'
- illicit decimal - The score for the category 'illicit'
- selfHarmIntent decimal - The score for the category 'self-harm/intent'
- hateThreatening decimal - The score for the category 'hate/threatening'
- sexualMinors decimal - The score for the category 'sexual/minors'
- harassmentThreatening decimal - The score for the category 'harassment/threatening'
- hate decimal - The score for the category 'hate'
- selfHarm decimal - The score for the category 'self-harm'
- sexual decimal - The score for the category 'sexual'
- violence decimal - The score for the category 'violence'
openai: CreateModerationResponseResults
Fields
- categoryScores CreateModerationResponseCategoryScores -
- flagged boolean - Whether any of the below categories are flagged
- categoryAppliedInputTypes CreateModerationResponseCategoryAppliedInputTypes -
- categories CreateModerationResponseCategories - A list of the categories, and whether they are flagged or not
openai: CreateResponse
Fields
- Fields Included from *ResponseProperties
- instructions string|()
- previousResponseId string|()
- reasoning Reasoning
- toolChoice ToolChoiceOptions|ToolChoiceTypes|ToolChoiceFunction
- model ModelIdsResponses
- text ResponsePropertiesText
- tools Tool[]
- truncation "disabled"|()|"auto"
- maxOutputTokens int|()
- anydata...
- Fields Included from *CreateResponseAllOf3
openai: CreateResponseAllOf3
Fields
- include? Includable[]? - Specify additional output data to include in the model response. Currently
supported values are:
file_search_call.results: Include the search results of the file search tool call.message.input_image.image_url: Include image urls from the input message.computer_call_output.output.image_url: Include image urls from the computer call output
- parallelToolCalls boolean?(default true) - Whether to allow the model to run tool calls in parallel
- 'stream boolean?(default false) - If set to true, the model response data will be streamed to the client as it is generated using server-sent events. See the Streaming section below for more information
- store boolean?(default true) - Whether to store the generated model response for later retrieval via API
openai: CreateRunQueries
Represents the Queries record for the operation: createRun
Fields
- include? ("step_details.tool_calls[*].file_search.results[*].content")[] - A list of additional fields to include in the response. Currently the only supported value is
step_details.tool_calls[*].file_search.results[*].contentto fetch the file search result content. See the file search tool documentation for more information
openai: CreateRunRequest
Fields
- reasoningEffort? ReasoningEffort? -
- instructions? string? - Overrides the instructions of the assistant. This is useful for modifying the behavior on a per-run basis
- additionalInstructions? string? - Appends additional instructions at the end of the instructions for the run. This is useful for modifying the behavior on a per-run basis without overriding other instructions
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- additionalMessages? CreateMessageRequest[]? - Adds additional messages to the thread before creating the run
- tools? AssistantObjectTools[]? - Override the tools the assistant can use for this run. This is useful for modifying the behavior on a per-run basis
- truncationStrategy? TruncationObject -
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering this or temperature but not both
- maxCompletionTokens? int? - The maximum number of completion tokens that may be used over the course of the run. The run will make a best effort to use only the number of completion tokens specified, across multiple turns of the run. If the run exceeds the number of completion tokens specified, the run will end with status
incomplete. Seeincomplete_detailsfor more info
- responseFormat? AssistantsApiResponseFormatOption -
- parallelToolCalls? ParallelToolCalls -
- 'stream? boolean? - If
true, returns a stream of events that happen during the Run as server-sent events, terminating when the Run enters a terminal state with adata: [DONE]message
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic
- toolChoice? AssistantsApiToolChoiceOption -
- model? string|AssistantSupportedModels? - The ID of the Model to be used to execute this run. If a value is provided here, it will override the model associated with the assistant. If not, the model associated with the assistant will be used
- maxPromptTokens? int? - The maximum number of prompt tokens that may be used over the course of the run. The run will make a best effort to use only the number of prompt tokens specified, across multiple turns of the run. If the run exceeds the number of prompt tokens specified, the run will end with status
incomplete. Seeincomplete_detailsfor more info
openai: CreateSpeechRequest
Fields
- voice VoiceIdsShared -
- input string - The text to generate audio for. The maximum length is 4096 characters
- instructions? string - Control the voice of your generated audio with additional instructions. Does not work with
tts-1ortts-1-hd
- responseFormat "mp3"|"opus"|"aac"|"flac"|"wav"|"pcm" (default "mp3") - The format to audio in. Supported formats are
mp3,opus,aac,flac,wav, andpcm
- model string|"tts-1"|"tts-1-hd"|"gpt-4o-mini-tts" - One of the available TTS models:
tts-1,tts-1-hdorgpt-4o-mini-tts
- speed decimal(default 1) - The speed of the generated audio. Select a value from
0.25to4.0.1.0is the default
openai: CreateThreadAndRunRequest
Fields
- instructions? string? - Override the default system message of the assistant. This is useful for modifying the behavior on a per-run basis
- toolResources? CreateThreadAndRunRequestToolResources? -
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- thread? CreateThreadRequest - Options to create a new thread. If no thread is provided when running a request, an empty thread will be created
- tools? AssistantObjectTools[]? - Override the tools the assistant can use for this run. This is useful for modifying the behavior on a per-run basis
- truncationStrategy? TruncationObject -
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering this or temperature but not both
- maxCompletionTokens? int? - The maximum number of completion tokens that may be used over the course of the run. The run will make a best effort to use only the number of completion tokens specified, across multiple turns of the run. If the run exceeds the number of completion tokens specified, the run will end with status
incomplete. Seeincomplete_detailsfor more info
- responseFormat? AssistantsApiResponseFormatOption -
- parallelToolCalls? ParallelToolCalls -
- 'stream? boolean? - If
true, returns a stream of events that happen during the Run as server-sent events, terminating when the Run enters a terminal state with adata: [DONE]message
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic
- toolChoice? AssistantsApiToolChoiceOption -
- model? string|"gpt-4.1"|"gpt-4.1-mini"|"gpt-4.1-nano"|"gpt-4.1-2025-04-14"|"gpt-4.1-mini-2025-04-14"|"gpt-4.1-nano-2025-04-14"|"gpt-4o"|"gpt-4o-2024-11-20"|"gpt-4o-2024-08-06"|"gpt-4o-2024-05-13"|"gpt-4o-mini"|"gpt-4o-mini-2024-07-18"|"gpt-4.5-preview"|"gpt-4.5-preview-2025-02-27"|"gpt-4-turbo"|"gpt-4-turbo-2024-04-09"|"gpt-4-0125-preview"|"gpt-4-turbo-preview"|"gpt-4-1106-preview"|"gpt-4-vision-preview"|"gpt-4"|"gpt-4-0314"|"gpt-4-0613"|"gpt-4-32k"|"gpt-4-32k-0314"|"gpt-4-32k-0613"|"gpt-3.5-turbo"|"gpt-3.5-turbo-16k"|"gpt-3.5-turbo-0613"|"gpt-3.5-turbo-1106"|"gpt-3.5-turbo-0125"|"gpt-3.5-turbo-16k-0613"? - The ID of the Model to be used to execute this run. If a value is provided here, it will override the model associated with the assistant. If not, the model associated with the assistant will be used
- maxPromptTokens? int? - The maximum number of prompt tokens that may be used over the course of the run. The run will make a best effort to use only the number of prompt tokens specified, across multiple turns of the run. If the run exceeds the number of prompt tokens specified, the run will end with status
incomplete. Seeincomplete_detailsfor more info
openai: CreateThreadAndRunRequestToolResources
A set of resources that are used by the assistant's tools. The resources are specific to the type of tool. For example, the code_interpreter tool requires a list of file IDs, while the file_search tool requires a list of vector store IDs
Fields
- codeInterpreter? CreateAssistantRequestToolResourcesCodeInterpreter -
- fileSearch? AssistantObjectToolResourcesFileSearch -
openai: CreateThreadRequest
Options to create a new thread. If no thread is provided when running a request, an empty thread will be created
Fields
- toolResources? CreateThreadRequestToolResources? -
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- messages? CreateMessageRequest[] - A list of messages to start the thread with
openai: CreateThreadRequestToolResources
A set of resources that are made available to the assistant's tools in this thread. The resources are specific to the type of tool. For example, the code_interpreter tool requires a list of file IDs, while the file_search tool requires a list of vector store IDs
Fields
- codeInterpreter? CreateAssistantRequestToolResourcesCodeInterpreter -
- fileSearch? CreateThreadRequestToolResourcesFileSearch -
openai: CreateTranscriptionRequest
Fields
- timestampGranularities ("word"|"segment")[](default ["segment"]) - The timestamp granularities to populate for this transcription.
response_formatmust be setverbose_jsonto use timestamp granularities. Either or both of these options are supported:word, orsegment. Note: There is no additional latency for segment timestamps, but generating word timestamps incurs additional latency
- file record { fileContent byte[], fileName string } - The audio file object (not file name) to transcribe, in one of these formats: flac, mp3, mp4, mpeg, mpga, m4a, ogg, wav, or webm
- responseFormat? AudioResponseFormat -
- 'stream boolean?(default false) - If set to true, the model response data will be streamed to the client
as it is generated using server-sent events.
See the Streaming section of the Speech-to-Text guide
for more information.
Note: Streaming is not supported for the
whisper-1model and will be ignored
- temperature decimal(default 0) - The sampling temperature, between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will use log probability to automatically increase the temperature until certain thresholds are hit
- model string|"whisper-1"|"gpt-4o-transcribe"|"gpt-4o-mini-transcribe" - ID of the model to use. The options are
gpt-4o-transcribe,gpt-4o-mini-transcribe, andwhisper-1(which is powered by our open source Whisper V2 model)
- include? TranscriptionInclude[] - Additional information to include in the transcription response.
logprobswill return the log probabilities of the tokens in the response to understand the model's confidence in the transcription.logprobsonly works with response_format set tojsonand only with the modelsgpt-4o-transcribeandgpt-4o-mini-transcribe
openai: CreateTranscriptionResponseJson
Represents a transcription response returned by model, based on the provided input
Fields
- text string - The transcribed text
- logprobs? CreateTranscriptionResponseJsonLogprobs[] - The log probabilities of the tokens in the transcription. Only returned with the models
gpt-4o-transcribeandgpt-4o-mini-transcribeiflogprobsis added to theincludearray
openai: CreateTranscriptionResponseJsonLogprobs
Fields
- logprob? decimal - The log probability of the token
- bytes? decimal[] - The bytes of the token
- token? string - The token in the transcription
openai: CreateTranscriptionResponseVerboseJson
Represents a verbose json transcription response returned by model, based on the provided input
Fields
- duration decimal - The duration of the input audio
- words? TranscriptionWord[] - Extracted words and their corresponding timestamps
- language string - The language of the input audio
- text string - The transcribed text
- segments? TranscriptionSegment[] - Segments of the transcribed text and their corresponding details
openai: CreateTranslationRequest
Fields
- file record { fileContent byte[], fileName string } - The audio file object (not file name) translate, in one of these formats: flac, mp3, mp4, mpeg, mpga, m4a, ogg, wav, or webm
- responseFormat "json"|"text"|"srt"|"verbose_json"|"vtt" (default "json") - The format of the output, in one of these options:
json,text,srt,verbose_json, orvtt
- temperature decimal(default 0) - The sampling temperature, between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will use log probability to automatically increase the temperature until certain thresholds are hit
- model string|"whisper-1" - ID of the model to use. Only
whisper-1(which is powered by our open source Whisper V2 model) is currently available
openai: CreateTranslationResponseJson
Fields
- text string -
openai: CreateTranslationResponseVerboseJson
Fields
- duration decimal - The duration of the input audio
- language string - The language of the output translation (always
english)
- text string - The translated text
- segments? TranscriptionSegment[] - Segments of the translated text and their corresponding details
openai: CreateUploadRequest
Fields
- filename string - The name of the file to upload
- purpose "assistants"|"batch"|"fine-tune"|"vision" - The intended purpose of the uploaded file. See the documentation on File purposes
- mimeType string - The MIME type of the file. This must fall within the supported MIME types for your file purpose. See the supported MIME types for assistants and vision
- bytes int - The number of bytes in the file you are uploading
openai: CreateVectorStoreFileBatchRequest
Fields
- chunkingStrategy? ChunkingStrategyRequestParam -
- attributes? VectorStoreFileAttributes? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
openai: CreateVectorStoreFileRequest
Fields
- chunkingStrategy? ChunkingStrategyRequestParam -
- attributes? VectorStoreFileAttributes? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
openai: CreateVectorStoreRequest
Fields
- chunkingStrategy? AutoChunkingStrategyRequestParam|StaticChunkingStrategyRequestParam - The chunking strategy used to chunk the file(s). If not set, will use the
autostrategy. Only applicable iffile_idsis non-empty
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- expiresAfter? VectorStoreExpirationAfter -
- name? string - The name of the vector store
openai: DataAllOf2
Fields
- id string - The identifier of the chat message
openai: DeleteAssistantResponse
Fields
- deleted boolean -
- id string -
- 'object "assistant.deleted" -
openai: DeleteCertificateResponse
Fields
- id string - The ID of the certificate that was deleted
- 'object "certificate.deleted" - The object type, must be
certificate.deleted
openai: DeleteFileResponse
Fields
- deleted boolean -
- id string -
- 'object "file" -
openai: DeleteFineTuningCheckpointPermissionResponse
Fields
- deleted boolean - Whether the fine-tuned model checkpoint permission was successfully deleted
- id string - The ID of the fine-tuned model checkpoint permission that was deleted
- 'object "checkpoint.permission" - The object type, which is always "checkpoint.permission"
openai: DeleteMessageResponse
Fields
- deleted boolean -
- id string -
- 'object "thread.message.deleted" -
openai: DeleteModelResponse
Fields
- deleted boolean -
- id string -
- 'object string -
openai: DeleteThreadResponse
Fields
- deleted boolean -
- id string -
- 'object "thread.deleted" -
openai: DeleteVectorStoreFileResponse
Fields
- deleted boolean -
- id string -
- 'object "vector_store.file.deleted" -
openai: DeleteVectorStoreResponse
Fields
- deleted boolean -
- id string -
- 'object "vector_store.deleted" -
openai: DoubleClick
A double click action
Fields
- x int - The x-coordinate where the double click occurred
- y int - The y-coordinate where the double click occurred
- 'type "double_click" (default "double_click") - Specifies the event type. For a double click action, this property is
always set to
double_click
openai: Drag
A drag action
Fields
- path Coordinate[] - An array of coordinates representing the path of the drag action. Coordinates will appear as an array
of objects, eg
[ { x: 100, y: 200 }, { x: 200, y: 300 } ]
- 'type "drag" (default "drag") - Specifies the event type. For a drag action, this property is
always set to
drag
openai: EasyInputMessage
A message input to the model with a role indicating instruction following
hierarchy. Instructions given with the developer or system role take
precedence over instructions given with the user role. Messages with the
assistant role are presumed to have been generated by the model in previous
interactions
Fields
- role "user"|"assistant"|"system"|"developer" - The role of the message input. One of
user,assistant,system, ordeveloper
- 'type? "message" - The type of the message input. Always
message
- content string|InputMessageContentList - Text, image, or audio input to the model, used to generate a response. Can also contain previous assistant responses
openai: EffectiveAt
Fields
- lt? int - Return only events whose
effective_at(Unix seconds) is less than this value
- gte? int - Return only events whose
effective_at(Unix seconds) is greater than or equal to this value
- lte? int - Return only events whose
effective_at(Unix seconds) is less than or equal to this value
- gt? int - Return only events whose
effective_at(Unix seconds) is greater than this value
openai: Embedding
Represents an embedding vector returned by embedding endpoint
Fields
- index int - The index of the embedding in the list of embeddings
- embedding decimal[] - The embedding vector, which is a list of floats. The length of vector depends on the model as listed in the embedding guide
- 'object "embedding" - The object type, which is always "embedding"
openai: Eval
An Eval object with a data source config and testing criteria. An Eval represents a task to be done for your LLM integration. Like:
- Improve the quality of my chatbot
- See how well my chatbot handles customer support
- Check if o3-mini is better at my usecase than gpt-4o
Fields
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- name string - The name of the evaluation
- testingCriteria EvalTestingCriteria[] - A list of testing criteria
- createdAt int - The Unix timestamp (in seconds) for when the eval was created
- id string - Unique identifier for the evaluation
- dataSourceConfig EvalCustomDataSourceConfig|EvalStoredCompletionsDataSourceConfig - Configuration of data sources used in runs of the evaluation
- 'object "eval" (default "eval") - The object type
openai: EvalApiError
An object representing an error response from the Eval API
Fields
- code string - The error code
- message string - The error message
openai: EvalCustomDataSourceConfig
A CustomDataSourceConfig which specifies the schema of your item and optionally sample namespaces.
The response schema defines the shape of the data that will be:
- Used to define your testing criteria and
- What data is required when creating a run
Fields
- schema record {} - The json schema for the run data source items. Learn how to build JSON schemas here
- 'type "custom" (default "custom") - The type of data source. Always
custom
openai: EvalItem
A message input to the model with a role indicating instruction following
hierarchy. Instructions given with the developer or system role take
precedence over instructions given with the user role. Messages with the
assistant role are presumed to have been generated by the model in previous
interactions
Fields
- role "user"|"assistant"|"system"|"developer" - The role of the message input. One of
user,assistant,system, ordeveloper
- 'type? "message" - The type of the message input. Always
message
- content string|InputTextContent|record { 'type "output_text" , text string } - Text inputs to the model - can contain template strings
openai: EvalJsonlFileContentSource
Fields
- 'type "file_content" (default "file_content") - The type of jsonl source. Always
file_content
- content EvalJsonlFileContentSourceContent[] - The content of the jsonl file
openai: EvalJsonlFileContentSourceContent
Fields
- item record {} -
- sample? record {} -
openai: EvalJsonlFileIdSource
Fields
- id string - The identifier of the file
- 'type "file_id" (default "file_id") - The type of jsonl source. Always
file_id
openai: EvalLabelModelGrader
A LabelModelGrader object which uses a model to assign labels to each item in the evaluation
Fields
- input EvalItem[] -
- name string - The name of the grader
- model string - The model to use for the evaluation. Must support structured outputs
- passingLabels string[] - The labels that indicate a passing result. Must be a subset of labels
- 'type "label_model" - The object type, which is always
label_model
- labels string[] - The labels to assign to each item in the evaluation
openai: EvalList
An object representing a list of evals
Fields
- firstId string - The identifier of the first eval in the data array
- data Eval[] - An array of eval objects
- lastId string - The identifier of the last eval in the data array
- hasMore boolean - Indicates whether there are more evals available
- 'object "list" (default "list") - The type of this object. It is always set to "list"
openai: EvalPythonGrader
A PythonGrader object that runs a python script on the input
Fields
- passThreshold? decimal - The threshold for the score
- name string - The name of the grader
- 'source string - The source code of the python script
- imageTag? string - The image tag to use for the python script
- 'type "python" - The object type, which is always
python
openai: EvalResponsesSource
A EvalResponsesSource object describing a run data source configuration
Fields
- reasoningEffort? ReasoningEffort? -
- topP? decimal? - Nucleus sampling parameter. This is a query parameter used to select responses
- metadata? record {}? - Metadata filter for the responses. This is a query parameter used to select responses
- createdAfter? int? - Only include items created after this timestamp (inclusive). This is a query parameter used to select responses
- createdBefore? int? - Only include items created before this timestamp (inclusive). This is a query parameter used to select responses
- instructionsSearch? string? - Optional search string for instructions. This is a query parameter used to select responses
- temperature? decimal? - Sampling temperature. This is a query parameter used to select responses
- allowParallelToolCalls? boolean? - Whether to allow parallel tool calls. This is a query parameter used to select responses
- model? string? - The name of the model to find responses for. This is a query parameter used to select responses
- 'type "responses" - The type of run data source. Always
responses
- hasToolCalls? boolean? - Whether the response has tool calls. This is a query parameter used to select responses
- users? string[]? - List of user identifiers. This is a query parameter used to select responses
openai: EvalRun
A schema representing an evaluation run
Fields
- perTestingCriteriaResults EvalRunPerTestingCriteriaResults[] - Results per testing criteria applied during the evaluation run
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- evalId string - The identifier of the associated evaluation
- reportUrl string - The URL to the rendered evaluation run report on the UI dashboard
- createdAt int - Unix timestamp (in seconds) when the evaluation run was created
- 'error EvalApiError - An object representing an error response from the Eval API
- dataSource CreateEvalJsonlRunDataSource|CreateEvalCompletionsRunDataSource|CreateEvalResponsesRunDataSource - Information about the run's data source
- resultCounts EvalRunResultCounts -
- name string - The name of the evaluation run
- model string - The model that is evaluated, if applicable
- id string - Unique identifier for the evaluation run
- perModelUsage EvalRunPerModelUsage[] - Usage statistics for each model during the evaluation run
- 'object "eval.run" (default "eval.run") - The type of the object. Always "eval.run"
- status string - The status of the evaluation run
openai: EvalRunList
An object representing a list of runs for an evaluation
Fields
- firstId string - The identifier of the first eval run in the data array
- data EvalRun[] - An array of eval run objects
- lastId string - The identifier of the last eval run in the data array
- hasMore boolean - Indicates whether there are more evals available
- 'object "list" (default "list") - The type of this object. It is always set to "list"
openai: EvalRunOutputItem
A schema representing an evaluation run output item
Fields
- datasourceItem record {} - Details of the input data source item
- runId string - The identifier of the evaluation run associated with this output item
- evalId string - The identifier of the evaluation group
- createdAt int - Unix timestamp (in seconds) when the evaluation run was created
- datasourceItemId int - The identifier for the data source item
- id string - Unique identifier for the evaluation run output item
- results record {}[] - A list of results from the evaluation run
- sample EvalRunOutputItemSample - A sample containing the input and output of the evaluation run
- 'object "eval.run.output_item" (default "eval.run.output_item") - The type of the object. Always "eval.run.output_item"
- status string - The status of the evaluation run
openai: EvalRunOutputItemList
An object representing a list of output items for an evaluation run
Fields
- firstId string - The identifier of the first eval run output item in the data array
- data EvalRunOutputItem[] - An array of eval run output item objects
- lastId string - The identifier of the last eval run output item in the data array
- hasMore boolean - Indicates whether there are more eval run output items available
- 'object "list" (default "list") - The type of this object. It is always set to "list"
openai: EvalRunOutputItemSample
A sample containing the input and output of the evaluation run
Fields
- output EvalRunOutputItemSampleOutput[] - An array of output messages
- topP decimal - The top_p value used for sampling
- input EvalRunOutputItemSampleInput[] - An array of input messages
- maxCompletionTokens int - The maximum number of tokens allowed for completion
- finishReason string - The reason why the sample generation was finished
- seed int - The seed used for generating the sample
- usage EvalRunOutputItemSampleUsage - Token usage details for the sample
- temperature decimal - The sampling temperature used
- model string - The model used for generating the sample
- 'error EvalApiError - An object representing an error response from the Eval API
openai: EvalRunOutputItemSampleInput
An input message
Fields
- role string - The role of the message sender (e.g., system, user, developer)
- content string - The content of the message
openai: EvalRunOutputItemSampleOutput
Fields
- role? string - The role of the message (e.g. "system", "assistant", "user")
- content? string - The content of the message
openai: EvalRunOutputItemSampleUsage
Token usage details for the sample
Fields
- completionTokens int - The number of completion tokens generated
- promptTokens int - The number of prompt tokens used
- totalTokens int - The total number of tokens used
- cachedTokens int - The number of tokens retrieved from cache
openai: EvalRunPerModelUsage
Fields
- completionTokens int - The number of completion tokens generated
- promptTokens int - The number of prompt tokens used
- modelName string - The name of the model
- totalTokens int - The total number of tokens used
- invocationCount int - The number of invocations
- cachedTokens int - The number of tokens retrieved from cache
openai: EvalRunPerTestingCriteriaResults
Fields
- testingCriteria string - A description of the testing criteria
- passed int - Number of tests passed for this criteria
- failed int - Number of tests failed for this criteria
openai: EvalRunResultCounts
Counters summarizing the outcomes of the evaluation run
Fields
- total int - Total number of executed output items
- failed int - Number of output items that failed to pass the evaluation
- passed int - Number of output items that passed the evaluation
- errored int - Number of output items that resulted in an error
openai: EvalScoreModelGrader
A ScoreModelGrader object that uses a model to assign a score to the input
Fields
- input EvalItem[] - The input text. This may include template strings
- passThreshold? decimal - The threshold for the score
- name string - The name of the grader
- range? decimal[] - The range of the score. Defaults to
[0, 1]
- model string - The model to use for the evaluation
- 'type "score_model" - The object type, which is always
score_model
- samplingParams? record {} - The sampling parameters for the model
openai: EvalsevalIdBody
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- name? string - Rename the evaluation
openai: EvalStoredCompletionsDataSourceConfig
A StoredCompletionsDataSourceConfig which specifies the metadata property of your stored completions query.
This is usually metadata like usecase=chatbot or prompt-version=v2, etc.
The schema returned by this data source config is used to defined what variables are available in your evals.
item and sample are both defined when using this data source config
Fields
- schema record {} - The json schema for the run data source items. Learn how to build JSON schemas here
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- 'type "stored_completions" (default "stored_completions") - The type of data source. Always
stored_completions
openai: EvalStoredCompletionsSource
A StoredCompletionsRunDataSource configuration describing a set of filters
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- createdAfter? int? - An optional Unix timestamp to filter items created after this time
- createdBefore? int? - An optional Unix timestamp to filter items created before this time
- 'limit? int? - An optional maximum number of items to return
- model? string? - An optional model to filter by (e.g., 'gpt-4o')
- 'type "stored_completions" (default "stored_completions") - The type of source. Always
stored_completions
openai: EvalStringCheckGrader
A StringCheckGrader object that performs a string comparison between input and reference using a specified operation
Fields
- reference string - The reference text. This may include template strings
- input string - The input text. This may include template strings
- name string - The name of the grader
- 'type "string_check" - The object type, which is always
string_check
- operation "eq"|"ne"|"like"|"ilike" - The string check operation to perform. One of
eq,ne,like, orilike
openai: EvalTextSimilarityGrader
A TextSimilarityGrader object which grades text based on similarity metrics
Fields
- reference string - The text being graded against
- input string - The text being graded
- passThreshold decimal - A float score where a value greater than or equal indicates a passing grade
- name? string - The name of the grader
- evaluationMetric "fuzzy_match"|"bleu"|"gleu"|"meteor"|"rouge_1"|"rouge_2"|"rouge_3"|"rouge_4"|"rouge_5"|"rouge_l" - The evaluation metric to use. One of
fuzzy_match,bleu,gleu,meteor,rouge_1,rouge_2,rouge_3,rouge_4,rouge_5, orrouge_l
- 'type "text_similarity" (default "text_similarity") - The type of grader
openai: FileCitationBody
A citation to a file
Fields
- fileId string - The ID of the file
- index int - The index of the file in the list of files
- 'type "file_citation" (default "file_citation") - The type of the file citation. Always
file_citation
openai: FilePath
A path to a file
Fields
- fileId string - The ID of the file
- index int - The index of the file in the list of files
- 'type "file_path" - The type of the file path. Always
file_path
openai: FileSearchRankingOptions
The ranking options for the file search. If not specified, the file search tool will use the auto ranker and a score_threshold of 0.
See the file search tool documentation for more information
Fields
- scoreThreshold decimal - The score threshold for the file search. All values must be a floating point number between 0 and 1
- ranker? FileSearchRanker - The ranker to use for the file search. If not specified will use the
autoranker
openai: FileSearchTool
A tool that searches for relevant content from uploaded files. Learn more about the file search tool
Fields
- vectorStoreIds string[] - The IDs of the vector stores to search
- maxNumResults? int - The maximum number of results to return. This number should be between 1 and 50 inclusive
- rankingOptions? RankingOptions -
- filters? anydata -
- 'type "file_search" (default "file_search") - The type of the file search tool. Always
file_search
openai: FileSearchToolCall
The results of a file search tool call. See the file search guide for more information
Fields
- id string - The unique ID of the file search tool call
- 'type "file_search_call" - The type of the file search tool call. Always
file_search_call
- queries string[] - The queries used to search for files
- results? FileSearchToolCallResults[]? - The results of the file search tool call
- status "in_progress"|"searching"|"completed"|"incomplete"|"failed" - The status of the file search tool call. One of
in_progress,searching,incompleteorfailed,
openai: FileSearchToolCallResults
Fields
- score? float - The relevance score of the file - a value between 0 and 1
- filename? string - The name of the file
- fileId? string - The unique ID of the file
- attributes? VectorStoreFileAttributes? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
- text? string - The text that was retrieved from the file
openai: FineTuneDPOMethod
Configuration for the DPO fine-tuning method
Fields
- hyperparameters? FineTuneDPOMethodHyperparameters - The hyperparameters used for the fine-tuning job
openai: FineTuneDPOMethodHyperparameters
The hyperparameters used for the fine-tuning job
Fields
- batchSize "auto"|int(default "auto") - Number of examples in each batch. A larger batch size means that model parameters are updated less frequently, but with lower variance
- nEpochs "auto"|int(default "auto") - The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset
- beta "auto"|decimal(default "auto") - The beta value for the DPO method. A higher beta value will increase the weight of the penalty between the policy and reference model
- learningRateMultiplier "auto"|decimal(default "auto") - Scaling factor for the learning rate. A smaller learning rate may be useful to avoid overfitting
openai: FineTuneMethod
The method used for fine-tuning
Fields
- supervised? FineTuneSupervisedMethod - Configuration for the supervised fine-tuning method
- dpo? FineTuneDPOMethod - Configuration for the DPO fine-tuning method
- 'type? "supervised"|"dpo" - The type of method. Is either
supervisedordpo
openai: FineTuneSupervisedMethod
Configuration for the supervised fine-tuning method
Fields
- hyperparameters? FineTuneSupervisedMethodHyperparameters - The hyperparameters used for the fine-tuning job
openai: FineTuneSupervisedMethodHyperparameters
The hyperparameters used for the fine-tuning job
Fields
- batchSize "auto"|int(default "auto") - Number of examples in each batch. A larger batch size means that model parameters are updated less frequently, but with lower variance
- nEpochs "auto"|int(default "auto") - The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset
- learningRateMultiplier "auto"|decimal(default "auto") - Scaling factor for the learning rate. A smaller learning rate may be useful to avoid overfitting
openai: FineTuningCheckpointPermission
The checkpoint.permission object represents a permission for a fine-tuned model checkpoint
Fields
- projectId string - The project identifier that the permission is for
- createdAt int - The Unix timestamp (in seconds) for when the permission was created
- id string - The permission identifier, which can be referenced in the API endpoints
- 'object "checkpoint.permission" - The object type, which is always "checkpoint.permission"
openai: FineTuningIntegration
Fields
- wandb CreateFineTuningJobRequestWandb - The settings for your integration with Weights and Biases. This payload specifies the project that metrics will be sent to. Optionally, you can set an explicit display name for your run, add tags to your run, and set a default entity (team, username, etc) to be associated with your run
- 'type "wandb" - The type of the integration being enabled for the fine-tuning job
openai: FineTuningJob
The fine_tuning.job object represents a fine-tuning job that has been created through the API
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- finishedAt int? - The Unix timestamp (in seconds) for when the fine-tuning job was finished. The value will be null if the fine-tuning job is still running
- seed int - The seed used for the fine-tuning job
- method? FineTuneMethod - The method used for fine-tuning
- fineTunedModel string? - The name of the fine-tuned model that is being created. The value will be null if the fine-tuning job is still running
- createdAt int - The Unix timestamp (in seconds) for when the fine-tuning job was created
- 'error FineTuningJobError? - For fine-tuning jobs that have
failed, this will contain more information on the cause of the failure
- estimatedFinish? int? - The Unix timestamp (in seconds) for when the fine-tuning job is estimated to finish. The value will be null if the fine-tuning job is not running
- organizationId string - The organization that owns the fine-tuning job
- hyperparameters FineTuningJobHyperparameters - The hyperparameters used for the fine-tuning job. This value will only be returned when running
supervisedjobs
- model string - The base model that is being fine-tuned
- id string - The object identifier, which can be referenced in the API endpoints
- trainedTokens int? - The total number of billable tokens processed by this fine-tuning job. The value will be null if the fine-tuning job is still running
- integrations? FineTuningJobIntegrations[]? - A list of integrations to enable for this fine-tuning job
- 'object "fine_tuning.job" - The object type, which is always "fine_tuning.job"
- status "validating_files"|"queued"|"running"|"succeeded"|"failed"|"cancelled" - The current status of the fine-tuning job, which can be either
validating_files,queued,running,succeeded,failed, orcancelled
openai: FineTuningJobCheckpoint
The fine_tuning.job.checkpoint object represents a model checkpoint for a fine-tuning job that is ready to use
Fields
- stepNumber int - The step number that the checkpoint was created at
- createdAt int - The Unix timestamp (in seconds) for when the checkpoint was created
- fineTuningJobId string - The name of the fine-tuning job that this checkpoint was created from
- id string - The checkpoint identifier, which can be referenced in the API endpoints
- metrics FineTuningJobCheckpointMetrics - Metrics at the step number during the fine-tuning job
- fineTunedModelCheckpoint string - The name of the fine-tuned checkpoint model that is created
- 'object "fine_tuning.job.checkpoint" - The object type, which is always "fine_tuning.job.checkpoint"
openai: FineTuningJobCheckpointMetrics
Metrics at the step number during the fine-tuning job
Fields
- fullValidMeanTokenAccuracy? decimal -
- validLoss? decimal -
- fullValidLoss? decimal -
- trainMeanTokenAccuracy? decimal -
- validMeanTokenAccuracy? decimal -
- trainLoss? decimal -
- step? decimal -
openai: FineTuningJobError
For fine-tuning jobs that have failed, this will contain more information on the cause of the failure
Fields
- code string - A machine-readable error code
- param string? - The parameter that was invalid, usually
training_fileorvalidation_file. This field will be null if the failure was not parameter-specific
- message string - A human-readable error message
openai: FineTuningJobEvent
Fine-tuning job event object
Fields
- data? record {} - The data associated with the event
- level "info"|"warn"|"error" - The log level of the event
- createdAt int - The Unix timestamp (in seconds) for when the fine-tuning job was created
- id string - The object identifier
- message string - The message of the event
- 'type? "message"|"metrics" - The type of event
- 'object "fine_tuning.job.event" - The object type, which is always "fine_tuning.job.event"
openai: FineTuningJobHyperparameters
The hyperparameters used for the fine-tuning job. This value will only be returned when running supervised jobs
Fields
- batchSize "auto"|int(default "auto") - Number of examples in each batch. A larger batch size means that model parameters are updated less frequently, but with lower variance
- nEpochs "auto"|int(default "auto") - The number of epochs to train the model for. An epoch refers to one full cycle through the training dataset
- learningRateMultiplier "auto"|decimal(default "auto") - Scaling factor for the learning rate. A smaller learning rate may be useful to avoid overfitting
openai: FunctionCallOutputItemParam
The output of a function tool call
Fields
- output string - A JSON string of the output of the function tool call
- id? anydata -
- 'type "function_call_output" (default "function_call_output") - The type of the function tool call output. Always
function_call_output
- callId string - The unique ID of the function tool call generated by the model
- status? anydata -
openai: FunctionObject
Fields
- name string - The name of the function to be called. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64
- description? string - A description of what the function does, used by the model to choose when and how to call the function
- strict boolean?(default false) - Whether to enable strict schema adherence when generating the function call. If set to true, the model will follow the exact schema defined in the
parametersfield. Only a subset of JSON Schema is supported whenstrictistrue. Learn more about Structured Outputs in the function calling guide
- parameters? FunctionParameters - The parameters the functions accepts, described as a JSON Schema object. See the guide for examples, and the JSON Schema reference for documentation about the format.
Omitting
parametersdefines a function with an empty parameter list
openai: FunctionParameters
The parameters the functions accepts, described as a JSON Schema object. See the guide for examples, and the JSON Schema reference for documentation about the format.
Omitting parameters defines a function with an empty parameter list
openai: FunctionTool
Defines a function in your own code the model can choose to call. Learn more about function calling
Fields
- name string - The name of the function to call
- description? anydata -
- 'type "function" (default "function") - The type of the function tool. Always
function
- strict anydata -
- parameters anydata -
openai: FunctionToolCall
A tool call to run a function. See the function calling guide for more information
Fields
- name string - The name of the function to run
- arguments string - A JSON string of the arguments to pass to the function
- id? string - The unique ID of the function tool call
- 'type "function_call" - The type of the function tool call. Always
function_call
- callId string - The unique ID of the function tool call generated by the model
- status? "in_progress"|"completed"|"incomplete" - The status of the item. One of
in_progress,completed, orincomplete. Populated when items are returned via API
openai: FunctionToolCallOutput
The output of a function tool call
Fields
- output string - A JSON string of the output of the function tool call
- id? string - The unique ID of the function tool call output. Populated when this item is returned via API
- 'type "function_call_output" - The type of the function tool call output. Always
function_call_output
- callId string - The unique ID of the function tool call generated by the model
- status? "in_progress"|"completed"|"incomplete" - The status of the item. One of
in_progress,completed, orincomplete. Populated when items are returned via API
openai: FunctionToolCallOutputResource
Fields
- Fields Included from *FunctionToolCallOutput
- Fields Included from *FunctionToolCallOutputResourceAllOf2
- anydata...
openai: FunctionToolCallOutputResourceAllOf2
openai: FunctionToolCallResource
Fields
- Fields Included from *FunctionToolCall
- Fields Included from *FunctionToolCallResourceAllOf2
- anydata...
openai: FunctionToolCallResourceAllOf2
openai: GetCertificateQueries
Represents the Queries record for the operation: getCertificate
Fields
- include? ("content")[] - A list of additional fields to include in the response. Currently the only supported value is
contentto fetch the PEM content of the certificate
openai: GetChatCompletionMessagesQueries
Represents the Queries record for the operation: getChatCompletionMessages
Fields
- 'limit int(default 20) - Number of messages to retrieve
- after? string - Identifier for the last message from the previous pagination request
- 'order "asc"|"desc" (default "asc") - Sort order for messages by timestamp. Use
ascfor ascending order ordescfor descending order. Defaults toasc
openai: GetEvalRunOutputItemsQueries
Represents the Queries record for the operation: getEvalRunOutputItems
Fields
- 'limit int(default 20) - Number of output items to retrieve
- after? string - Identifier for the last output item from the previous pagination request
- status? "fail"|"pass" - Filter output items by status. Use
failedto filter by failed output items orpassto filter by passed output items
- 'order "asc"|"desc" (default "asc") - Sort order for output items by timestamp. Use
ascfor ascending order ordescfor descending order. Defaults toasc
openai: GetEvalRunsQueries
Represents the Queries record for the operation: getEvalRuns
Fields
- 'limit int(default 20) - Number of runs to retrieve
- after? string - Identifier for the last run from the previous pagination request
- 'order "asc"|"desc" (default "asc") - Sort order for runs by timestamp. Use
ascfor ascending order ordescfor descending order. Defaults toasc
- status? "queued"|"in_progress"|"completed"|"canceled"|"failed" - Filter runs by status. One of
queued|in_progress|failed|completed|canceled
openai: GetResponseQueries
Represents the Queries record for the operation: getResponse
Fields
- include? Includable[] - Additional fields to include in the response. See the
includeparameter for Response creation above for more information
openai: GetRunStepQueries
Represents the Queries record for the operation: getRunStep
Fields
- include? ("step_details.tool_calls[*].file_search.results[*].content")[] - A list of additional fields to include in the response. Currently the only supported value is
step_details.tool_calls[*].file_search.results[*].contentto fetch the file search result content. See the file search tool documentation for more information
openai: Image
Represents the content or the URL of an image generated by the OpenAI API
Fields
- revisedPrompt? string - For
dall-e-3only, the revised prompt that was used to generate the image
- b64Json? string - The base64-encoded JSON of the generated image. Default value for
gpt-image-1, and only present ifresponse_formatis set tob64_jsonfordall-e-2anddall-e-3
- url? string - When using
dall-e-2ordall-e-3, the URL of the generated image ifresponse_formatis set tourl(default value). Unsupported forgpt-image-1
openai: ImagesResponse
The response from the image generation endpoint
Fields
- data? Image[] - The list of generated images
- created int - The Unix timestamp (in seconds) of when the image was created
- usage? ImagesResponseUsage - For
gpt-image-1only, the token usage information for the image generation
openai: ImagesResponseUsage
For gpt-image-1 only, the token usage information for the image generation
Fields
- inputTokensDetails ImagesResponseUsageInputTokensDetails -
- totalTokens int - The total number of tokens (images and text) used for the image generation
- outputTokens int - The number of image tokens in the output image
- inputTokens int - The number of tokens (images and text) in the input prompt
openai: ImagesResponseUsageInputTokensDetails
The input tokens detailed information for the image generation
Fields
- textTokens int - The number of text tokens in the input prompt
- imageTokens int - The number of image tokens in the input prompt
openai: InlineResponse2002
Fields
- deleted boolean -
- evalId string -
- 'object string -
openai: InlineResponse2003
Fields
- deleted? boolean -
- runId? string -
- 'object? string -
openai: InlineResponse2004
Fields
- deleted? boolean -
- id? string -
- 'object? string -
openai: InputFileContent
A file input to the model
Fields
- filename? string - The name of the file to be sent to the model
- fileId? anydata -
- 'type "input_file" (default "input_file") - The type of the input item. Always
input_file
- fileData? string - The content of the file to be sent to the model
openai: InputImageContent
An image input to the model. Learn about image inputs
Fields
- imageUrl? anydata -
- fileId? anydata -
- detail "low"|"high"|"auto" - The detail level of the image to be sent to the model. One of
high,low, orauto. Defaults toauto
- 'type "input_image" (default "input_image") - The type of the input item. Always
input_image
openai: InputMessage
A message input to the model with a role indicating instruction following
hierarchy. Instructions given with the developer or system role take
precedence over instructions given with the user role
Fields
- role "user"|"system"|"developer" - The role of the message input. One of
user,system, ordeveloper
- 'type? "message" - The type of the message input. Always set to
message
- content InputMessageContentList - A list of one or many input items to the model, containing different content types
- status? "in_progress"|"completed"|"incomplete" - The status of item. One of
in_progress,completed, orincomplete. Populated when items are returned via API
openai: InputMessageResource
Fields
- Fields Included from *InputMessage
- role "user"|"system"|"developer"
- type "message"
- content InputMessageContentList
- status "in_progress"|"completed"|"incomplete"
- anydata...
- Fields Included from *InputMessageResourceAllOf2
- id string
- anydata...
openai: InputMessageResourceAllOf2
Fields
- id string - The unique ID of the message input
openai: InputTextContent
A text input to the model
Fields
- text string - The text input to the model
- 'type "input_text" (default "input_text") - The type of the input item. Always
input_text
openai: Invite
Represents an individual invite to the organization
Fields
- role "owner"|"reader" -
ownerorreader
- expiresAt int - The Unix timestamp (in seconds) of when the invite expires
- projects? InviteProjects[] - The projects that were granted membership upon acceptance of the invite
- invitedAt int - The Unix timestamp (in seconds) of when the invite was sent
- id string - The identifier, which can be referenced in API endpoints
- acceptedAt? int - The Unix timestamp (in seconds) of when the invite was accepted
- email string - The email address of the individual to whom the invite was sent
- 'object "organization.invite" - The object type, which is always
organization.invite
- status "accepted"|"expired"|"pending" -
accepted,expired, orpending
openai: InviteDeleteResponse
Fields
- deleted boolean -
- id string -
- 'object "organization.invite.deleted" - The object type, which is always
organization.invite.deleted
openai: InviteListResponse
Fields
- firstId? string - The first
invite_idin the retrievedlist
- data Invite[] -
- lastId? string - The last
invite_idin the retrievedlist
- hasMore? boolean - The
has_moreproperty is used for pagination to indicate there are additional results
- 'object "list" - The object type, which is always
list
openai: InviteProjects
Fields
- role? "member"|"owner" - Project membership role
- id? string - Project's public ID
openai: InviteRequest
Fields
- role "reader"|"owner" -
ownerorreader
- projects? InviteRequestProjects[] - An array of projects to which membership is granted at the same time the org invite is accepted. If omitted, the user will be invited to the default project for compatibility with legacy behavior
- email string - Send an email to this address
openai: InviteRequestProjects
Fields
- role "member"|"owner" - Project membership role
- id string - Project's public ID
openai: ItemReferenceParam
An internal identifier for an item to reference
Fields
- id string - The ID of the item to reference
- 'type? anydata -
openai: JSONSchema
Structured Outputs configuration options, including a JSON Schema
Fields
- schema? ResponseFormatJsonSchemaSchema - The schema for the response format, described as a JSON Schema object. Learn how to build JSON schemas here
- name string - The name of the response format. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64
- description? string - A description of what the response format is for, used by the model to determine how to respond in the format
- strict boolean?(default false) - Whether to enable strict schema adherence when generating the output.
If set to true, the model will always follow the exact schema defined
in the
schemafield. Only a subset of JSON Schema is supported whenstrictistrue. To learn more, read the Structured Outputs guide
openai: KeyPress
A collection of keypresses the model would like to perform
Fields
- keys string[] - The combination of keys the model is requesting to be pressed. This is an array of strings, each representing a key
- 'type "keypress" (default "keypress") - Specifies the event type. For a keypress action, this property is
always set to
keypress
openai: ListAssistantsQueries
Represents the Queries record for the operation: listAssistants
Fields
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListAssistantsResponse
Fields
- firstId string -
- data AssistantObject[] -
- lastId string -
- hasMore boolean -
- 'object string -
openai: ListAuditLogsQueries
Represents the Queries record for the operation: list-audit-logs
Fields
- eventTypes? AuditLogEventType[] - Return only events with a
typein one of these values. For example,project.created. For all options, see the documentation for the audit log object
- effectiveAt? EffectiveAt - Return only events whose
effective_at(Unix seconds) is in this range
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- actorEmails? string[] - Return only events performed by users with these emails
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- resourceIds? string[] - Return only events performed on these targets. For example, a project ID updated
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- actorIds? string[] - Return only events performed by these actors. Can be a user ID, a service account ID, or an api key tracking ID
- projectIds? string[] - Return only events for these projects
openai: ListAuditLogsResponse
Fields
- firstId string -
- data AuditLog[] -
- lastId string -
- hasMore boolean -
- 'object "list" -
openai: ListBatchesQueries
Represents the Queries record for the operation: listBatches
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListBatchesResponse
Fields
- firstId? string -
- data Batch[] -
- lastId? string -
- hasMore boolean -
- 'object "list" -
openai: ListCertificatesResponse
Fields
- firstId? string -
- data Certificate[] -
- lastId? string -
- hasMore boolean -
- 'object "list" -
openai: ListChatCompletionsQueries
Represents the Queries record for the operation: listChatCompletions
Fields
- metadata? Metadata? - A list of metadata keys to filter the Chat Completions by. Example:
metadata[key1]=value1&metadata[key2]=value2
- 'limit int(default 20) - Number of Chat Completions to retrieve
- model? string - The model used to generate the Chat Completions
- after? string - Identifier for the last chat completion from the previous pagination request
- 'order "asc"|"desc" (default "asc") - Sort order for Chat Completions by timestamp. Use
ascfor ascending order ordescfor descending order. Defaults toasc
openai: ListEvalsQueries
Represents the Queries record for the operation: listEvals
Fields
- 'limit int(default 20) - Number of evals to retrieve
- orderBy "created_at"|"updated_at" (default "created_at") - Evals can be ordered by creation time or last updated time. Use
created_atfor creation time orupdated_atfor last updated time
- after? string - Identifier for the last eval from the previous pagination request
- 'order "asc"|"desc" (default "asc") - Sort order for evals by timestamp. Use
ascfor ascending order ordescfor descending order
openai: ListFilesInVectorStoreBatchQueries
Represents the Queries record for the operation: listFilesInVectorStoreBatch
Fields
- filter? "in_progress"|"completed"|"failed"|"cancelled" - Filter by file status. One of
in_progress,completed,failed,cancelled
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListFilesQueries
Represents the Queries record for the operation: listFiles
Fields
- purpose? string - Only return files with the given purpose
- 'limit int(default 10000) - A limit on the number of objects to be returned. Limit can range between 1 and 10,000, and the default is 10,000
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListFilesResponse
Fields
- firstId string -
- data OpenAIFile[] -
- lastId string -
- hasMore boolean -
- 'object string -
openai: ListFineTuningCheckpointPermissionResponse
Fields
- firstId? string? -
- data FineTuningCheckpointPermission[] -
- lastId? string? -
- hasMore boolean -
- 'object "list" -
openai: ListFineTuningCheckpointPermissionsQueries
Represents the Queries record for the operation: listFineTuningCheckpointPermissions
Fields
- projectId? string - The ID of the project to get permissions for
- 'limit int(default 10) - Number of permissions to retrieve
- after? string - Identifier for the last permission ID from the previous pagination request
- 'order "ascending"|"descending" (default "descending") - The order in which to retrieve permissions
openai: ListFineTuningEventsQueries
Represents the Queries record for the operation: listFineTuningEvents
Fields
- 'limit int(default 20) - Number of events to retrieve
- after? string - Identifier for the last event from the previous pagination request
openai: ListFineTuningJobCheckpointsQueries
Represents the Queries record for the operation: listFineTuningJobCheckpoints
Fields
- 'limit int(default 10) - Number of checkpoints to retrieve
- after? string - Identifier for the last checkpoint ID from the previous pagination request
openai: ListFineTuningJobCheckpointsResponse
Fields
- firstId? string? -
- data FineTuningJobCheckpoint[] -
- lastId? string? -
- hasMore boolean -
- 'object "list" -
openai: ListFineTuningJobEventsResponse
Fields
- data FineTuningJobEvent[] -
- hasMore boolean -
- 'object "list" -
openai: ListInputItemsQueries
Represents the Queries record for the operation: listInputItems
Fields
- include? Includable[] - Additional fields to include in the response. See the
includeparameter for Response creation above for more information
- before? string - An item ID to list items before, used in pagination
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - An item ID to list items after, used in pagination
- 'order? "asc"|"desc" - The order to return the input items in. Default is
asc.asc: Return the input items in ascending order.desc: Return the input items in descending order
openai: ListInvitesQueries
Represents the Queries record for the operation: list-invites
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListMessagesQueries
Represents the Queries record for the operation: listMessages
Fields
- runId? string - Filter messages by the run ID that generated them
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListMessagesResponse
Fields
- 'object string -
- data MessageObject[] -
- first_id string -
- last_id string -
- has_more boolean -
openai: ListModelsResponse
Fields
- data Model[] -
- 'object "list" -
openai: ListOrganizationCertificatesQueries
Represents the Queries record for the operation: listOrganizationCertificates
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListPaginatedFineTuningJobsQueries
Represents the Queries record for the operation: listPaginatedFineTuningJobs
Fields
- metadata? record { string... }? - Optional metadata filter. To filter, use the syntax
metadata[k]=v. Alternatively, setmetadata=nullto indicate no metadata
- 'limit int(default 20) - Number of fine-tuning jobs to retrieve
- after? string - Identifier for the last job from the previous pagination request
openai: ListPaginatedFineTuningJobsResponse
Fields
- data FineTuningJob[] -
- hasMore boolean -
- 'object "list" -
openai: ListProjectApiKeysQueries
Represents the Queries record for the operation: list-project-api-keys
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListProjectCertificatesQueries
Represents the Queries record for the operation: listProjectCertificates
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListProjectRateLimitsQueries
Represents the Queries record for the operation: list-project-rate-limits
Fields
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, beginning with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 100) - A limit on the number of objects to be returned. The default is 100
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListProjectServiceAccountsQueries
Represents the Queries record for the operation: list-project-service-accounts
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListProjectsQueries
Represents the Queries record for the operation: list-projects
Fields
- includeArchived boolean(default false) - If
truereturns all projects including those that have beenarchived. Archived projects are not included by default
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListProjectUsersQueries
Represents the Queries record for the operation: list-project-users
Fields
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListRunsQueries
Represents the Queries record for the operation: listRuns
Fields
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListRunsResponse
Fields
- firstId string -
- data RunObject[] -
- lastId string -
- hasMore boolean -
- 'object string -
openai: ListRunStepsQueries
Represents the Queries record for the operation: listRunSteps
Fields
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- include? ("step_details.tool_calls[*].file_search.results[*].content")[] - A list of additional fields to include in the response. Currently the only supported value is
step_details.tool_calls[*].file_search.results[*].contentto fetch the file search result content. See the file search tool documentation for more information
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListRunStepsResponse
Fields
- 'object string -
- data RunStepObject[] -
- first_id string -
- last_id string -
- has_more boolean -
openai: ListUsersQueries
Represents the Queries record for the operation: list-users
Fields
- emails? string[] - Filter by the email address of users
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
openai: ListVectorStoreFilesQueries
Represents the Queries record for the operation: listVectorStoreFiles
Fields
- filter? "in_progress"|"completed"|"failed"|"cancelled" - Filter by file status. One of
in_progress,completed,failed,cancelled
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListVectorStoreFilesResponse
Fields
- 'object string -
- data VectorStoreFileObject[] -
- first_id string -
- last_id string -
- has_more boolean -
openai: ListVectorStoresQueries
Represents the Queries record for the operation: listVectorStores
Fields
- before? string - A cursor for use in pagination.
beforeis an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, starting with obj_foo, your subsequent call can include before=obj_foo in order to fetch the previous page of the list
- 'limit int(default 20) - A limit on the number of objects to be returned. Limit can range between 1 and 100, and the default is 20
- after? string - A cursor for use in pagination.
afteris an object ID that defines your place in the list. For instance, if you make a list request and receive 100 objects, ending with obj_foo, your subsequent call can include after=obj_foo in order to fetch the next page of the list
- 'order "asc"|"desc" (default "desc") - Sort order by the
created_attimestamp of the objects.ascfor ascending order anddescfor descending order
openai: ListVectorStoresResponse
Fields
- 'object string -
- data VectorStoreObject[] -
- first_id string -
- last_id string -
- has_more boolean -
openai: MessageContentImageFileObject
References an image File in the content of a message
Fields
- imageFile MessageContentImageFileObjectImageFile -
- 'type "image_file" - Always
image_file
openai: MessageContentImageFileObjectImageFile
Fields
- detail "auto"|"low"|"high" (default "auto") - Specifies the detail level of the image if specified by the user.
lowuses fewer tokens, you can opt in to high resolution usinghigh
openai: MessageContentImageUrlObject
References an image URL in the content of a message
Fields
- imageUrl MessageContentImageUrlObjectImageUrl -
- 'type "image_url" - The type of the content part
openai: MessageContentImageUrlObjectImageUrl
Fields
- detail "auto"|"low"|"high" (default "auto") - Specifies the detail level of the image.
lowuses fewer tokens, you can opt in to high resolution usinghigh. Default value isauto
- url string - The external URL of the image, must be a supported image types: jpeg, jpg, png, gif, webp
openai: MessageContentRefusalObject
The refusal content generated by the assistant
Fields
- refusal string -
- 'type "refusal" - Always
refusal
openai: MessageContentTextAnnotationsFileCitationObject
A citation within the message that points to a specific quote from a specific File associated with the assistant or the message. Generated when the assistant uses the "file_search" tool to search files
Fields
- startIndex int -
- fileCitation MessageContentTextAnnotationsFileCitationObjectFileCitation -
- endIndex int -
- text string - The text in the message content that needs to be replaced
- 'type "file_citation" - Always
file_citation
openai: MessageContentTextAnnotationsFileCitationObjectFileCitation
Fields
- fileId string - The ID of the specific File the citation is from
openai: MessageContentTextAnnotationsFilePathObject
A URL for the file that's generated when the assistant used the code_interpreter tool to generate a file
Fields
- startIndex int -
- endIndex int -
- text string - The text in the message content that needs to be replaced
- 'type "file_path" - Always
file_path
openai: MessageContentTextAnnotationsFilePathObjectFilePath
Fields
- fileId string - The ID of the file that was generated
openai: MessageContentTextObject
The text content that is part of a message
Fields
- text MessageContentTextObjectText -
- 'type "text" - Always
text
openai: MessageContentTextObjectText
Fields
- annotations MessageContentTextObjectTextAnnotations[] -
- value string - The data that makes up the text
openai: MessageObject
Represents a message within a thread
Fields
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- role "user"|"assistant" - The entity that produced the message. One of
userorassistant
- attachments CreateMessageRequestAttachments[]? - A list of files attached to the message, and the tools they were added to
- createdAt int - The Unix timestamp (in seconds) for when the message was created
- content MessageObjectContent[] - The content of the message in array of text and/or images
- completedAt int? - The Unix timestamp (in seconds) for when the message was completed
- id string - The identifier, which can be referenced in API endpoints
- incompleteAt int? - The Unix timestamp (in seconds) for when the message was marked as incomplete
- incompleteDetails MessageObjectIncompleteDetails? -
- 'object "thread.message" - The object type, which is always
thread.message
- status "in_progress"|"incomplete"|"completed" - The status of the message, which can be either
in_progress,incomplete, orcompleted
openai: MessageObjectIncompleteDetails
On an incomplete message, details about why the message is incomplete
Fields
- reason "content_filter"|"max_tokens"|"run_cancelled"|"run_expired"|"run_failed" - The reason the message is incomplete
openai: MessageRequestContentTextObject
The text content that is part of a message
Fields
- text string - Text content to be sent to the model
- 'type "text" - Always
text
openai: Metadata
Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard.
Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
Fields
- string... - Rest field
openai: Model
Describes an OpenAI model offering that can be used with the API
Fields
- id string - The model identifier, which can be referenced in the API endpoints.
- created int - The Unix timestamp (in seconds) when the model was created.
- 'object "model" - The object type, which is always "model".
- owned_by string - The organization that owns the model.
openai: ModelResponseProperties
Fields
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling,
where the model considers the results of the tokens with top_p probability
mass. So 0.1 means only the tokens comprising the top 10% probability mass
are considered.
We generally recommend altering this or
temperaturebut not both
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
We generally recommend altering this or
top_pbut not both
- serviceTier? ServiceTier? -
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more
openai: ModifyAssistantRequest
Fields
- reasoningEffort? ReasoningEffort? -
- topP decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering this or temperature but not both
- instructions? string? - The system instructions that the assistant uses. The maximum length is 256,000 characters
- toolResources? ModifyAssistantRequestToolResources? -
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- responseFormat? AssistantsApiResponseFormatOption -
- name? string? - The name of the assistant. The maximum length is 256 characters
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic
- description? string? - The description of the assistant. The maximum length is 512 characters
- model? string|AssistantSupportedModels - ID of the model to use. You can use the List models API to see all of your available models, or see our Model overview for descriptions of them
- tools AssistantObjectTools[](default []) - A list of tool enabled on the assistant. There can be a maximum of 128 tools per assistant. Tools can be of types
code_interpreter,file_search, orfunction
openai: ModifyAssistantRequestToolResources
A set of resources that are used by the assistant's tools. The resources are specific to the type of tool. For example, the code_interpreter tool requires a list of file IDs, while the file_search tool requires a list of vector store IDs
Fields
- codeInterpreter? ModifyAssistantRequestToolResourcesCodeInterpreter -
- fileSearch? ModifyAssistantRequestToolResourcesFileSearch -
openai: ModifyAssistantRequestToolResourcesCodeInterpreter
Fields
openai: ModifyAssistantRequestToolResourcesFileSearch
Fields
- vectorStoreIds? string[] - Overrides the vector store attached to this assistant. There can be a maximum of 1 vector store attached to the assistant
openai: ModifyCertificateRequest
Fields
- name string - The updated name for the certificate
openai: ModifyMessageRequest
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
openai: ModifyRunRequest
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
openai: ModifyThreadRequest
Fields
- toolResources? ModifyThreadRequestToolResources? -
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
openai: ModifyThreadRequestToolResources
A set of resources that are made available to the assistant's tools in this thread. The resources are specific to the type of tool. For example, the code_interpreter tool requires a list of file IDs, while the file_search tool requires a list of vector store IDs
Fields
- codeInterpreter? CreateAssistantRequestToolResourcesCodeInterpreter -
- fileSearch? ModifyThreadRequestToolResourcesFileSearch -
openai: ModifyThreadRequestToolResourcesFileSearch
Fields
- vectorStoreIds? string[] - The vector store attached to this thread. There can be a maximum of 1 vector store attached to the thread
openai: Move
A mouse move action
Fields
- x int - The x-coordinate to move to
- y int - The y-coordinate to move to
- 'type "move" (default "move") - Specifies the event type. For a move action, this property is
always set to
move
openai: OpenAIFile
The File object represents a document that has been uploaded to OpenAI
Fields
- id string - The file identifier, which can be referenced in the API endpoints.
- bytes int - The size of the file, in bytes.
- created_at int - The Unix timestamp (in seconds) for when the file was created.
- expires_at? int - The Unix timestamp (in seconds) for when the file will expire.
- filename string - The name of the file.
- 'object "file" - The object type, which is always
file.
- purpose "assistants"|"assistants_output"|"batch"|"batch_output"|"fine-tune"|"fine-tune-results"|"vision" - The intended purpose of the file. Supported values are
assistants,assistants_output,batch,batch_output,fine-tune,fine-tune-resultsandvision.
- status "uploaded"|"processed"|"error" - Deprecated. The current status of the file, which can be either
uploaded,processed, orerror.
- status_details? string - Deprecated. For details on why a fine-tuning training file failed validation, see the
errorfield onfine_tuning.job.
openai: OrganizationAdminApiKeysBody
Fields
- name string -
openai: OtherChunkingStrategyResponseParam
This is returned when the chunking strategy is unknown. Typically, this is because the file was indexed before the chunking_strategy concept was introduced in the API
Fields
- 'type "other" - Always
other
openai: OutputMessage
An output message from the model
Fields
- role "assistant" - The role of the output message. Always
assistant
- id string - The unique ID of the output message
- 'type "message" - The type of the output message. Always
message
- content OutputContent[] - The content of the output message
- status "in_progress"|"completed"|"incomplete" - The status of the message input. One of
in_progress,completed, orincomplete. Populated when input items are returned via API
openai: OutputTextContent
A text output from the model
Fields
- annotations Annotation[] - The annotations of the text output
- text string - The text output from the model
- 'type "output_text" (default "output_text") - The type of the output text. Always
output_text
openai: PredictionContent
Static predicted output content, such as the content of a text file that is being regenerated
Fields
- 'type "content" - The type of the predicted content you want to provide. This type is
currently always
content
- content string|ChatCompletionRequestMessageContentPartText[] - The content that should be matched when generating a model response. If generated tokens would match this content, the entire model response can be returned much more quickly
openai: Project
Represents an individual project
Fields
- archivedAt? int? - The Unix timestamp (in seconds) of when the project was archived or
null
- name string - The name of the project. This appears in reporting
- createdAt int - The Unix timestamp (in seconds) of when the project was created
- id string - The identifier, which can be referenced in API endpoints
- 'object "organization.project" - The object type, which is always
organization.project
- status "active"|"archived" -
activeorarchived
openai: ProjectApiKey
Represents an individual API key in a project
Fields
- owner ProjectApiKeyOwner -
- lastUsedAt int - The Unix timestamp (in seconds) of when the API key was last used
- name string - The name of the API key
- createdAt int - The Unix timestamp (in seconds) of when the API key was created
- redactedValue string - The redacted value of the API key
- id string - The identifier, which can be referenced in API endpoints
- 'object "organization.project.api_key" - The object type, which is always
organization.project.api_key
openai: ProjectApiKeyDeleteResponse
Fields
- deleted boolean -
- id string -
- 'object "organization.project.api_key.deleted" -
openai: ProjectApiKeyListResponse
Fields
- firstId string -
- data ProjectApiKey[] -
- lastId string -
- hasMore boolean -
- 'object "list" -
openai: ProjectApiKeyOwner
Fields
- serviceAccount? ProjectServiceAccount -
- 'type? "user"|"service_account" -
userorservice_account
- user? ProjectUser - Represents an individual user in a project
openai: ProjectCreateRequest
Fields
- name string - The friendly name of the project, this name appears in reports
openai: ProjectListResponse
Fields
- firstId string -
- data Project[] -
- lastId string -
- hasMore boolean -
- 'object "list" -
openai: ProjectRateLimit
Represents a project rate limit config
Fields
- batch1DayMaxInputTokens? int - The maximum batch input tokens per day. Only present for relevant models
- maxTokensPer1Minute int - The maximum tokens per minute
- model string - The model this rate limit applies to
- id string - The identifier, which can be referenced in API endpoints
- maxImagesPer1Minute? int - The maximum images per minute. Only present for relevant models
- maxAudioMegabytesPer1Minute? int - The maximum audio megabytes per minute. Only present for relevant models
- maxRequestsPer1Minute int - The maximum requests per minute
- 'object "project.rate_limit" - The object type, which is always
project.rate_limit
- maxRequestsPer1Day? int - The maximum requests per day. Only present for relevant models
openai: ProjectRateLimitListResponse
Fields
- firstId string -
- data ProjectRateLimit[] -
- lastId string -
- hasMore boolean -
- 'object "list" -
openai: ProjectRateLimitUpdateRequest
Fields
- batch1DayMaxInputTokens? int - The maximum batch input tokens per day. Only relevant for certain models
- maxTokensPer1Minute? int - The maximum tokens per minute
- maxImagesPer1Minute? int - The maximum images per minute. Only relevant for certain models
- maxAudioMegabytesPer1Minute? int - The maximum audio megabytes per minute. Only relevant for certain models
- maxRequestsPer1Minute? int - The maximum requests per minute
- maxRequestsPer1Day? int - The maximum requests per day. Only relevant for certain models
openai: ProjectServiceAccount
Represents an individual service account in a project
Fields
- role "owner"|"member" -
ownerormember
- name string - The name of the service account
- createdAt int - The Unix timestamp (in seconds) of when the service account was created
- id string - The identifier, which can be referenced in API endpoints
- 'object "organization.project.service_account" - The object type, which is always
organization.project.service_account
openai: ProjectServiceAccountApiKey
Fields
- name string -
- createdAt int -
- id string -
- value string -
- 'object "organization.project.service_account.api_key" - The object type, which is always
organization.project.service_account.api_key
openai: ProjectServiceAccountCreateRequest
Fields
- name string - The name of the service account being created
openai: ProjectServiceAccountCreateResponse
Fields
- role "member" - Service accounts can only have one role of type
member
- apiKey ProjectServiceAccountApiKey -
- name string -
- createdAt int -
- id string -
- 'object "organization.project.service_account" -
openai: ProjectServiceAccountDeleteResponse
Fields
- deleted boolean -
- id string -
- 'object "organization.project.service_account.deleted" -
openai: ProjectServiceAccountListResponse
Fields
- firstId string -
- data ProjectServiceAccount[] -
- lastId string -
- hasMore boolean -
- 'object "list" -
openai: ProjectUpdateRequest
Fields
- name string - The updated name of the project, this name appears in reports
openai: ProjectUser
Represents an individual user in a project
Fields
- addedAt int - The Unix timestamp (in seconds) of when the project was added
- role "owner"|"member" -
ownerormember
- name string - The name of the user
- id string - The identifier, which can be referenced in API endpoints
- email string - The email address of the user
- 'object "organization.project.user" - The object type, which is always
organization.project.user
openai: ProjectUserCreateRequest
Fields
- role "owner"|"member" -
ownerormember
- userId string - The ID of the user
openai: ProjectUserDeleteResponse
Fields
- deleted boolean -
- id string -
- 'object "organization.project.user.deleted" -
openai: ProjectUserListResponse
Fields
- firstId string -
- data ProjectUser[] -
- lastId string -
- hasMore boolean -
- 'object string -
openai: ProjectUserUpdateRequest
Fields
- role "owner"|"member" -
ownerormember
openai: RankingOptions
Fields
- scoreThreshold? decimal - The score threshold for the file search, a number between 0 and 1. Numbers closer to 1 will attempt to return only the most relevant results, but may return fewer results
- ranker? "auto"|"default-2024-11-15" - The ranker to use for the file search
openai: RealtimeResponseCreateParamsTools
Fields
- name? string - The name of the function
- description? string - The description of the function, including guidance on when and how to call it, and guidance about what to tell the user when calling (if anything)
- 'type? "function" - The type of the tool, i.e.
function
- parameters? record {} - Parameters of the function in JSON Schema
openai: RealtimeSessionCreateRequest
Realtime session object configuration
Fields
- voice? VoiceIdsShared -
- instructions? string - The default system instructions (i.e. system message) prepended to model calls. This field allows the client to guide the model on desired responses. The model can be instructed on response content and format, (e.g. "be extremely succinct", "act friendly", "here are examples of good responses") and on audio behavior (e.g. "talk quickly", "inject emotion into your voice", "laugh frequently"). The instructions are not guaranteed to be followed by the model, but they provide guidance to the model on the desired behavior.
Note that the server sets default instructions which will be used if this field is not set and are visible in the
session.createdevent at the start of the session
- inputAudioFormat "pcm16"|"g711_ulaw"|"g711_alaw" (default "pcm16") - The format of input audio. Options are
pcm16,g711_ulaw, org711_alaw. Forpcm16, input audio must be 16-bit PCM at a 24kHz sample rate, single channel (mono), and little-endian byte order
- inputAudioNoiseReduction? RealtimeSessionInputAudioNoiseReduction -
- inputAudioTranscription? RealtimeSessionInputAudioTranscription -
- turnDetection? RealtimeSessionTurnDetection -
- tools? RealtimeResponseCreateParamsTools[] - Tools (functions) available to the model
- modalities? ("text"|"audio")[] - The set of modalities the model can respond with. To disable audio, set this to ["text"]
- maxResponseOutputTokens? int|"inf" - Maximum number of output tokens for a single assistant response,
inclusive of tool calls. Provide an integer between 1 and 4096 to
limit output tokens, or
inffor the maximum available tokens for a given model. Defaults toinf
- outputAudioFormat "pcm16"|"g711_ulaw"|"g711_alaw" (default "pcm16") - The format of output audio. Options are
pcm16,g711_ulaw, org711_alaw. Forpcm16, output audio is sampled at a rate of 24kHz
- temperature decimal(default 0.8) - Sampling temperature for the model, limited to [0.6, 1.2]. For audio models a temperature of 0.8 is highly recommended for best performance
- toolChoice string(default "auto") - How the model chooses tools. Options are
auto,none,required, or specify a function
- model? "gpt-4o-realtime-preview"|"gpt-4o-realtime-preview-2024-10-01"|"gpt-4o-realtime-preview-2024-12-17"|"gpt-4o-mini-realtime-preview"|"gpt-4o-mini-realtime-preview-2024-12-17" - The Realtime model used for this session
openai: RealtimeSessionCreateResponse
A new Realtime session configuration, with an ephermeral key. Default TTL for keys is one minute
Fields
- voice? VoiceIdsShared -
- instructions? string - The default system instructions (i.e. system message) prepended to model
calls. This field allows the client to guide the model on desired
responses. The model can be instructed on response content and format,
(e.g. "be extremely succinct", "act friendly", "here are examples of good
responses") and on audio behavior (e.g. "talk quickly", "inject emotion
into your voice", "laugh frequently"). The instructions are not guaranteed
to be followed by the model, but they provide guidance to the model on the
desired behavior.
Note that the server sets default instructions which will be used if this
field is not set and are visible in the
session.createdevent at the start of the session
- inputAudioFormat? string - The format of input audio. Options are
pcm16,g711_ulaw, org711_alaw
- modalities? ("text"|"audio")[] - The set of modalities the model can respond with. To disable audio, set this to ["text"]
- maxResponseOutputTokens? int|"inf" - Maximum number of output tokens for a single assistant response,
inclusive of tool calls. Provide an integer between 1 and 4096 to
limit output tokens, or
inffor the maximum available tokens for a given model. Defaults toinf
- outputAudioFormat? string - The format of output audio. Options are
pcm16,g711_ulaw, org711_alaw
- inputAudioTranscription? RealtimeSessionCreateResponseInputAudioTranscription -
- temperature? decimal - Sampling temperature for the model, limited to [0.6, 1.2]. Defaults to 0.8
- turnDetection? RealtimeSessionCreateResponseTurnDetection -
- toolChoice? string - How the model chooses tools. Options are
auto,none,required, or specify a function
- clientSecret RealtimeSessionCreateResponseClientSecret -
- tools? RealtimeResponseCreateParamsTools[] - Tools (functions) available to the model
openai: RealtimeSessionCreateResponseClientSecret
Ephemeral key returned by the API
Fields
- expiresAt int - Timestamp for when the token expires. Currently, all tokens expire after one minute
- value string - Ephemeral key usable in client environments to authenticate connections to the Realtime API. Use this in client-side environments rather than a standard API token, which should only be used server-side
openai: RealtimeSessionCreateResponseInputAudioTranscription
Configuration for input audio transcription, defaults to off and can be
set to null to turn off once on. Input audio transcription is not native
to the model, since the model consumes audio directly. Transcription runs
asynchronously through Whisper and should be treated as rough guidance
rather than the representation understood by the model
Fields
- model? string - The model to use for transcription,
whisper-1is the only currently supported model
openai: RealtimeSessionCreateResponseTurnDetection
Configuration for turn detection. Can be set to null to turn off. Server
VAD means that the model will detect the start and end of speech based on
audio volume and respond at the end of user speech
Fields
- silenceDurationMs? int - Duration of silence to detect speech stop (in milliseconds). Defaults to 500ms. With shorter values the model will respond more quickly, but may jump in on short pauses from the user
- prefixPaddingMs? int - Amount of audio to include before the VAD detected speech (in milliseconds). Defaults to 300ms
- threshold? decimal - Activation threshold for VAD (0.0 to 1.0), this defaults to 0.5. A higher threshold will require louder audio to activate the model, and thus might perform better in noisy environments
- 'type? string - Type of turn detection, only
server_vadis currently supported
openai: RealtimeSessionInputAudioNoiseReduction
Configuration for input audio noise reduction. This can be set to null to turn off.
Noise reduction filters audio added to the input audio buffer before it is sent to VAD and the model.
Filtering the audio can improve VAD and turn detection accuracy (reducing false positives) and model performance by improving perception of the input audio
Fields
- 'type? "near_field"|"far_field" - Type of noise reduction.
near_fieldis for close-talking microphones such as headphones,far_fieldis for far-field microphones such as laptop or conference room microphones
openai: RealtimeSessionInputAudioTranscription
Configuration for input audio transcription, defaults to off and can be set to null to turn off once on. Input audio transcription is not native to the model, since the model consumes audio directly. Transcription runs asynchronously through the /audio/transcriptions endpoint and should be treated as guidance of input audio content rather than precisely what the model heard. The client can optionally set the language and prompt for transcription, these offer additional guidance to the transcription service
Fields
- model? string - The model to use for transcription, current options are
gpt-4o-transcribe,gpt-4o-mini-transcribe, andwhisper-1
- prompt? string - An optional text to guide the model's style or continue a previous audio
segment.
For
whisper-1, the prompt is a list of keywords. Forgpt-4o-transcribemodels, the prompt is a free text string, for example "expect words related to technology"
openai: RealtimeSessionTurnDetection
Configuration for turn detection, ether Server VAD or Semantic VAD. This can be set to null to turn off, in which case the client must manually trigger model response.
Server VAD means that the model will detect the start and end of speech based on audio volume and respond at the end of user speech.
Semantic VAD is more advanced and uses a turn detection model (in conjuction with VAD) to semantically estimate whether the user has finished speaking, then dynamically sets a timeout based on this probability. For example, if user audio trails off with "uhhm", the model will score a low probability of turn end and wait longer for the user to continue speaking. This can be useful for more natural conversations, but may have a higher latency
Fields
- silenceDurationMs? int - Used only for
server_vadmode. Duration of silence to detect speech stop (in milliseconds). Defaults to 500ms. With shorter values the model will respond more quickly, but may jump in on short pauses from the user
- createResponse boolean(default true) - Whether or not to automatically generate a response when a VAD stop event occurs
- interruptResponse boolean(default true) - Whether or not to automatically interrupt any ongoing response with output to the default
conversation (i.e.
conversationofauto) when a VAD start event occurs
- prefixPaddingMs? int - Used only for
server_vadmode. Amount of audio to include before the VAD detected speech (in milliseconds). Defaults to 300ms
- eagerness "low"|"medium"|"high"|"auto" (default "auto") - Used only for
semantic_vadmode. The eagerness of the model to respond.lowwill wait longer for the user to continue speaking,highwill respond more quickly.autois the default and is equivalent tomedium
- threshold? decimal - Used only for
server_vadmode. Activation threshold for VAD (0.0 to 1.0), this defaults to 0.5. A higher threshold will require louder audio to activate the model, and thus might perform better in noisy environments
- 'type "server_vad"|"semantic_vad" (default "server_vad") - Type of turn detection
openai: RealtimeTranscriptionSessionCreateRequest
Realtime transcription session object configuration
Fields
- inputAudioFormat "pcm16"|"g711_ulaw"|"g711_alaw" (default "pcm16") - The format of input audio. Options are
pcm16,g711_ulaw, org711_alaw. Forpcm16, input audio must be 16-bit PCM at a 24kHz sample rate, single channel (mono), and little-endian byte order
- include? string[] - The set of items to include in the transcription. Current available items are:
item.input_audio_transcription.logprobs
- modalities? ("text"|"audio")[] - The set of modalities the model can respond with. To disable audio, set this to ["text"]
- inputAudioNoiseReduction? RealtimeSessionInputAudioNoiseReduction -
- inputAudioTranscription? RealtimeTranscriptionSessionCreateRequestInputAudioTranscription -
- turnDetection? RealtimeTranscriptionSessionCreateRequestTurnDetection -
openai: RealtimeTranscriptionSessionCreateRequestInputAudioTranscription
Configuration for input audio transcription. The client can optionally set the language and prompt for transcription, these offer additional guidance to the transcription service
Fields
- model? "gpt-4o-transcribe"|"gpt-4o-mini-transcribe"|"whisper-1" - The model to use for transcription, current options are
gpt-4o-transcribe,gpt-4o-mini-transcribe, andwhisper-1
- prompt? string - An optional text to guide the model's style or continue a previous audio
segment.
For
whisper-1, the prompt is a list of keywords. Forgpt-4o-transcribemodels, the prompt is a free text string, for example "expect words related to technology"
openai: RealtimeTranscriptionSessionCreateRequestTurnDetection
Configuration for turn detection, ether Server VAD or Semantic VAD. This can be set to null to turn off, in which case the client must manually trigger model response.
Server VAD means that the model will detect the start and end of speech based on audio volume and respond at the end of user speech.
Semantic VAD is more advanced and uses a turn detection model (in conjuction with VAD) to semantically estimate whether the user has finished speaking, then dynamically sets a timeout based on this probability. For example, if user audio trails off with "uhhm", the model will score a low probability of turn end and wait longer for the user to continue speaking. This can be useful for more natural conversations, but may have a higher latency
Fields
- silenceDurationMs? int - Used only for
server_vadmode. Duration of silence to detect speech stop (in milliseconds). Defaults to 500ms. With shorter values the model will respond more quickly, but may jump in on short pauses from the user
- createResponse boolean(default true) - Whether or not to automatically generate a response when a VAD stop event occurs. Not available for transcription sessions
- interruptResponse boolean(default true) - Whether or not to automatically interrupt any ongoing response with output to the default
conversation (i.e.
conversationofauto) when a VAD start event occurs. Not available for transcription sessions
- prefixPaddingMs? int - Used only for
server_vadmode. Amount of audio to include before the VAD detected speech (in milliseconds). Defaults to 300ms
- eagerness "low"|"medium"|"high"|"auto" (default "auto") - Used only for
semantic_vadmode. The eagerness of the model to respond.lowwill wait longer for the user to continue speaking,highwill respond more quickly.autois the default and is equivalent tomedium
- threshold? decimal - Used only for
server_vadmode. Activation threshold for VAD (0.0 to 1.0), this defaults to 0.5. A higher threshold will require louder audio to activate the model, and thus might perform better in noisy environments
- 'type "server_vad"|"semantic_vad" (default "server_vad") - Type of turn detection
openai: RealtimeTranscriptionSessionCreateResponse
A new Realtime transcription session configuration.
When a session is created on the server via REST API, the session object also contains an ephemeral key. Default TTL for keys is one minute. This property is not present when a session is updated via the WebSocket API
Fields
- inputAudioFormat? string - The format of input audio. Options are
pcm16,g711_ulaw, org711_alaw
- modalities? ("text"|"audio")[] - The set of modalities the model can respond with. To disable audio, set this to ["text"]
- inputAudioTranscription? RealtimeTranscriptionSessionCreateResponseInputAudioTranscription -
- turnDetection? RealtimeSessionCreateResponseTurnDetection -
- clientSecret RealtimeTranscriptionSessionCreateResponseClientSecret -
openai: RealtimeTranscriptionSessionCreateResponseClientSecret
Ephemeral key returned by the API. Only present when the session is created on the server via REST API
Fields
- expiresAt int - Timestamp for when the token expires. Currently, all tokens expire after one minute
- value string - Ephemeral key usable in client environments to authenticate connections to the Realtime API. Use this in client-side environments rather than a standard API token, which should only be used server-side
openai: RealtimeTranscriptionSessionCreateResponseInputAudioTranscription
Configuration of the transcription model
Fields
- model? "gpt-4o-transcribe"|"gpt-4o-mini-transcribe"|"whisper-1" - The model to use for transcription. Can be
gpt-4o-transcribe,gpt-4o-mini-transcribe, orwhisper-1
openai: Reasoning
o-series models only
Configuration options for reasoning models
Fields
- summary? "auto"|"concise"|"detailed"? - A summary of the reasoning performed by the model. This can be
useful for debugging and understanding the model's reasoning process.
One of
auto,concise, ordetailed
- effort? ReasoningEffort? - o-series models only
Constrains effort on reasoning for
reasoning models.
Currently supported values are
low,medium, andhigh. Reducing reasoning effort can result in faster responses and fewer tokens used on reasoning in a response
- generateSummary? "auto"|"concise"|"detailed"? - Deprecated: use
summaryinstead. A summary of the reasoning performed by the model. This can be useful for debugging and understanding the model's reasoning process. One ofauto,concise, ordetailed
openai: ReasoningItem
A description of the chain of thought used by a reasoning model while generating a response
Fields
- summary ReasoningItemSummary[] - Reasoning text contents
- id string - The unique identifier of the reasoning content
- 'type "reasoning" - The type of the object. Always
reasoning
- status? "in_progress"|"completed"|"incomplete" - The status of the item. One of
in_progress,completed, orincomplete. Populated when items are returned via API
openai: ReasoningItemSummary
Fields
- text string - A short summary of the reasoning used by the model when generating the response
- 'type "summary_text" - The type of the object. Always
summary_text
openai: RefusalContent
A refusal from the model
Fields
- refusal string - The refusal explanationfrom the model
- 'type "refusal" (default "refusal") - The type of the refusal. Always
refusal
openai: Response
Fields
- Fields Included from *ModelResponseProperties
- Fields Included from *ResponseProperties
- instructions string|()
- previousResponseId string|()
- reasoning Reasoning
- toolChoice ToolChoiceOptions|ToolChoiceTypes|ToolChoiceFunction
- model ModelIdsResponses
- text ResponsePropertiesText
- tools Tool[]
- truncation "disabled"|()|"auto"
- maxOutputTokens int|()
- anydata...
- Fields Included from *ResponseAllOf3
- output OutputItem[]
- parallelToolCalls boolean
- outputText string|()
- usage ResponseUsage
- createdAt decimal
- id string
- error ResponseError|()
- incompleteDetails ResponseIncompleteDetails|()
- object "response"
- status "completed"|"failed"|"in_progress"|"incomplete"
- anydata...
openai: ResponseAllOf3
Fields
- output OutputItem[] - An array of content items generated by the model.
- The length and order of items in the
outputarray is dependent on the model's response. - Rather than accessing the first item in the
outputarray and assuming it's anassistantmessage with the content generated by the model, you might consider using theoutput_textproperty where supported in SDKs
- The length and order of items in the
- parallelToolCalls boolean(default true) - Whether to allow the model to run tool calls in parallel
- outputText? string? - SDK-only convenience property that contains the aggregated text output
from all
output_textitems in theoutputarray, if any are present. Supported in the Python and JavaScript SDKs
- usage? ResponseUsage - Represents token usage details including input tokens, output tokens, a breakdown of output tokens, and the total tokens used
- createdAt decimal - Unix timestamp (in seconds) of when this Response was created
- id string - Unique identifier for this Response
- 'error ResponseError? - An error object returned when the model fails to generate a Response
- incompleteDetails ResponseIncompleteDetails? -
- 'object "response" - The object type of this resource - always set to
response
- status? "completed"|"failed"|"in_progress"|"incomplete" - The status of the response generation. One of
completed,failed,in_progress, orincomplete
openai: ResponseError
An error object returned when the model fails to generate a Response
Fields
- code ResponseErrorCode - The error code for the response
- message string - A human-readable description of the error
openai: ResponseFormatJsonObject
JSON object response format. An older method of generating JSON responses.
Using json_schema is recommended for models that support it. Note that the
model will not generate JSON without a system or user message instructing it
to do so
Fields
- 'type "json_object" - The type of response format being defined. Always
json_object
openai: ResponseFormatJsonSchema
JSON Schema response format. Used to generate structured JSON responses. Learn more about Structured Outputs
Fields
- jsonSchema JSONSchema -
- 'type "json_schema" - The type of response format being defined. Always
json_schema
openai: ResponseFormatJsonSchemaSchema
The schema for the response format, described as a JSON Schema object. Learn how to build JSON schemas here
openai: ResponseFormatText
Default response format. Used to generate text responses
Fields
- 'type "text" - The type of response format being defined. Always
text
openai: ResponseIncompleteDetails
Details about why the response is incomplete
Fields
- reason? "max_output_tokens"|"content_filter" - The reason why the response is incomplete
openai: ResponseItemList
A list of Response items
Fields
- firstId string - The ID of the first item in the list
- data ItemResource[] - A list of items used to generate this response
- lastId string - The ID of the last item in the list
- hasMore boolean - Whether there are more items available
- 'object "list" - The type of object returned, must be
list
openai: ResponseProperties
Fields
- instructions? string? - Inserts a system (or developer) message as the first item in the model's context.
When using along with
previous_response_id, the instructions from a previous response will not be carried over to the next response. This makes it simple to swap out system (or developer) messages in new responses
- previousResponseId? string? - The unique ID of the previous response to the model. Use this to create multi-turn conversations. Learn more about conversation state
- reasoning? Reasoning - o-series models only Configuration options for reasoning models
- toolChoice? ToolChoiceOptions|ToolChoiceTypes|ToolChoiceFunction - How the model should select which tool (or tools) to use when generating
a response. See the
toolsparameter to see how to specify which tools the model can call
- model? ModelIdsResponses -
- text? ResponsePropertiesText - Configuration options for a text response from the model. Can be plain text or structured JSON data. Learn more:
- tools? Tool[] - An array of tools the model may call while generating a response. You
can specify which tool to use by setting the
tool_choiceparameter. The two categories of tools you can provide the model are:- Built-in tools: Tools that are provided by OpenAI that extend the model's capabilities, like web search or file search. Learn more about built-in tools.
- Function calls (custom tools): Functions that are defined by you, enabling the model to call your own code. Learn more about function calling
- truncation "auto"|"disabled"?(default "disabled") - The truncation strategy to use for the model response.
auto: If the context of this response and previous ones exceeds the model's context window size, the model will truncate the response to fit the context window by dropping input items in the middle of the conversation.disabled(default): If a model response will exceed the context window size for a model, the request will fail with a 400 error
- maxOutputTokens? int? - An upper bound for the number of tokens that can be generated for a response, including visible output tokens and reasoning tokens
openai: ResponsePropertiesText
Configuration options for a text response from the model. Can be plain text or structured JSON data. Learn more:
Fields
- format? TextResponseFormatConfiguration - An object specifying the format that the model must output.
Configuring
{ "type": "json_schema" }enables Structured Outputs, which ensures the model will match your supplied JSON schema. Learn more in the Structured Outputs guide. The default format is{ "type": "text" }with no additional options. Not recommended for gpt-4o and newer models: Setting to{ "type": "json_object" }enables the older JSON mode, which ensures the message the model generates is valid JSON. Usingjson_schemais preferred for models that support it
openai: ResponseUsage
Represents token usage details including input tokens, output tokens, a breakdown of output tokens, and the total tokens used
Fields
- inputTokensDetails ResponseUsageInputTokensDetails -
- totalTokens int - The total number of tokens used
- outputTokens int - The number of output tokens
- inputTokens int - The number of input tokens
- outputTokensDetails ResponseUsageOutputTokensDetails -
openai: ResponseUsageInputTokensDetails
A detailed breakdown of the input tokens
Fields
- cachedTokens int - The number of tokens that were retrieved from the cache. More on prompt caching
openai: ResponseUsageOutputTokensDetails
A detailed breakdown of the output tokens
Fields
- reasoningTokens int - The number of reasoning tokens
openai: RunCompletionUsage
Usage statistics related to the run. This value will be null if the run is not in a terminal state (i.e. in_progress, queued, etc.)
Fields
- completionTokens int - Number of completion tokens used over the course of the run
- promptTokens int - Number of prompt tokens used over the course of the run
- totalTokens int - Total number of tokens used (prompt + completion)
openai: RunObject
Represents an execution run on a thread
Fields
- cancelledAt int? - The Unix timestamp (in seconds) for when the run was cancelled
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- requiredAction RunObjectRequiredAction? -
- usage RunCompletionUsage? - Usage statistics related to the run. This value will be
nullif the run is not in a terminal state (i.e.in_progress,queued, etc.)
- createdAt int - The Unix timestamp (in seconds) for when the run was created
- tools AssistantObjectTools[](default []) - The list of tools that the assistant used for this run
- topP? decimal? - The nucleus sampling value used for this run. If not set, defaults to 1
- maxCompletionTokens int? - The maximum number of completion tokens specified to have been used over the course of the run
- expiresAt int? - The Unix timestamp (in seconds) for when the run will expire
- responseFormat AssistantsApiResponseFormatOption -
- temperature? decimal? - The sampling temperature used for this run. If not set, defaults to 1
- toolChoice AssistantsApiToolChoiceOption -
- id string - The identifier, which can be referenced in API endpoints
- lastError RunObjectLastError? -
- incompleteDetails RunObjectIncompleteDetails? -
- truncationStrategy TruncationObject -
- completedAt int? - The Unix timestamp (in seconds) for when the run was completed
- parallelToolCalls ParallelToolCalls -
- startedAt int? - The Unix timestamp (in seconds) for when the run was started
- failedAt int? - The Unix timestamp (in seconds) for when the run failed
- maxPromptTokens int? - The maximum number of prompt tokens specified to have been used over the course of the run
- 'object "thread.run" - The object type, which is always
thread.run
- status "queued"|"in_progress"|"requires_action"|"cancelling"|"cancelled"|"failed"|"completed"|"incomplete"|"expired" - The status of the run, which can be either
queued,in_progress,requires_action,cancelling,cancelled,failed,completed,incomplete, orexpired
openai: RunObjectIncompleteDetails
Details on why the run is incomplete. Will be null if the run is not incomplete
Fields
- reason? "max_completion_tokens"|"max_prompt_tokens" - The reason why the run is incomplete. This will point to which specific token limit was reached over the course of the run
openai: RunObjectLastError
The last error associated with this run. Will be null if there are no errors
Fields
- code "server_error"|"rate_limit_exceeded"|"invalid_prompt" - One of
server_error,rate_limit_exceeded, orinvalid_prompt
- message string - A human-readable description of the error
openai: RunObjectRequiredAction
Details on the action required to continue the run. Will be null if no action is required
Fields
- submitToolOutputs RunObjectRequiredActionSubmitToolOutputs -
- 'type "submit_tool_outputs" - For now, this is always
submit_tool_outputs
openai: RunObjectRequiredActionSubmitToolOutputs
Details on the tool outputs needed for this run to continue
Fields
- toolCalls RunToolCallObject[] - A list of the relevant tool calls
openai: RunStepCompletionUsage
Usage statistics related to the run step. This value will be null while the run step's status is in_progress
Fields
- completionTokens int - Number of completion tokens used over the course of the run step
- promptTokens int - Number of prompt tokens used over the course of the run step
- totalTokens int - Total number of tokens used (prompt + completion)
openai: RunStepDetailsMessageCreationObject
Details of the message creation by the run step
Fields
- messageCreation RunStepDetailsMessageCreationObjectMessageCreation -
- 'type "message_creation" - Always
message_creation
openai: RunStepDetailsMessageCreationObjectMessageCreation
Fields
- messageId string - The ID of the message that was created by this run step
openai: RunStepDetailsToolCallsCodeObject
Details of the Code Interpreter tool call the run step was involved in
Fields
- codeInterpreter RunStepDetailsToolCallsCodeObjectCodeInterpreter -
- id string - The ID of the tool call
- 'type "code_interpreter" - The type of tool call. This is always going to be
code_interpreterfor this type of tool call
openai: RunStepDetailsToolCallsCodeObjectCodeInterpreter
The Code Interpreter tool call definition
Fields
- outputs RunStepDetailsToolCallsCodeObjectCodeInterpreterOutputs[] - The outputs from the Code Interpreter tool call. Code Interpreter can output one or more items, including text (
logs) or images (image). Each of these are represented by a different object type
- input string - The input to the Code Interpreter tool call
openai: RunStepDetailsToolCallsCodeOutputImageObject
Fields
- 'type "image" - Always
image
openai: RunStepDetailsToolCallsCodeOutputImageObjectImage
Fields
openai: RunStepDetailsToolCallsCodeOutputLogsObject
Text output from the Code Interpreter tool call as part of a run step
Fields
- 'type "logs" - Always
logs
- logs string - The text output from the Code Interpreter tool call
openai: RunStepDetailsToolCallsFileSearchObject
Fields
- fileSearch RunStepDetailsToolCallsFileSearchObjectFileSearch -
- id string - The ID of the tool call object
- 'type "file_search" - The type of tool call. This is always going to be
file_searchfor this type of tool call
openai: RunStepDetailsToolCallsFileSearchObjectFileSearch
For now, this is always going to be an empty object
Fields
- rankingOptions? RunStepDetailsToolCallsFileSearchRankingOptionsObject -
- results? RunStepDetailsToolCallsFileSearchResultObject[] - The results of the file search
openai: RunStepDetailsToolCallsFileSearchRankingOptionsObject
The ranking options for the file search
Fields
- scoreThreshold decimal - The score threshold for the file search. All values must be a floating point number between 0 and 1
- ranker FileSearchRanker - The ranker to use for the file search. If not specified will use the
autoranker
openai: RunStepDetailsToolCallsFileSearchResultObject
A result instance of the file search
Fields
- score decimal - The score of the result. All values must be a floating point number between 0 and 1
- fileName string - The name of the file that result was found in
- fileId string - The ID of the file that result was found in
- content? RunStepDetailsToolCallsFileSearchResultObjectContent[] - The content of the result that was found. The content is only included if requested via the include query parameter
openai: RunStepDetailsToolCallsFileSearchResultObjectContent
Fields
- text? string - The text content of the file
- 'type? "text" - The type of the content
openai: RunStepDetailsToolCallsFunctionObject
Fields
- 'function RunStepDetailsToolCallsFunctionObjectFunction - The definition of the function that was called
- id string - The ID of the tool call object
- 'type "function" - The type of tool call. This is always going to be
functionfor this type of tool call
openai: RunStepDetailsToolCallsFunctionObjectFunction
The definition of the function that was called
Fields
- name string - The name of the function
- arguments string - The arguments passed to the function
openai: RunStepDetailsToolCallsObject
Details of the tool call
Fields
- toolCalls RunStepDetailsToolCallsObjectToolCalls[] - An array of tool calls the run step was involved in. These can be associated with one of three types of tools:
code_interpreter,file_search, orfunction
- 'type "tool_calls" - Always
tool_calls
openai: RunStepObject
Represents a step in execution of a run
Fields
- cancelledAt int? - The Unix timestamp (in seconds) for when the run step was cancelled
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- usage RunStepCompletionUsage? - Usage statistics related to the run step. This value will be
nullwhile the run step's status isin_progress
- createdAt int - The Unix timestamp (in seconds) for when the run step was created
- expiredAt int? - The Unix timestamp (in seconds) for when the run step expired. A step is considered expired if the parent run is expired
- 'type "message_creation"|"tool_calls" - The type of run step, which can be either
message_creationortool_calls
- stepDetails RunStepDetailsMessageCreationObject|RunStepDetailsToolCallsObject - The details of the run step
- completedAt int? - The Unix timestamp (in seconds) for when the run step completed
- id string - The identifier of the run step, which can be referenced in API endpoints
- lastError RunStepObjectLastError? -
- failedAt int? - The Unix timestamp (in seconds) for when the run step failed
- 'object "thread.run.step" - The object type, which is always
thread.run.step
- status "in_progress"|"cancelled"|"failed"|"completed"|"expired" - The status of the run step, which can be either
in_progress,cancelled,failed,completed, orexpired
openai: RunStepObjectLastError
The last error associated with this run step. Will be null if there are no errors
Fields
- code "server_error"|"rate_limit_exceeded" - One of
server_errororrate_limit_exceeded
- message string - A human-readable description of the error
openai: RunToolCallObject
Tool call objects
Fields
- 'function RunToolCallObjectFunction - The function definition
- id string - The ID of the tool call. This ID must be referenced when you submit the tool outputs in using the Submit tool outputs to run endpoint
- 'type "function" - The type of tool call the output is required for. For now, this is always
function
openai: RunToolCallObjectFunction
The function definition
Fields
- name string - The name of the function
- arguments string - The arguments that the model expects you to pass to the function
openai: Screenshot
A screenshot action
Fields
- 'type "screenshot" (default "screenshot") - Specifies the event type. For a screenshot action, this property is
always set to
screenshot
openai: Scroll
A scroll action
Fields
- scrollY int - The vertical scroll distance
- scrollX int - The horizontal scroll distance
- x int - The x-coordinate where the scroll occurred
- y int - The y-coordinate where the scroll occurred
- 'type "scroll" (default "scroll") - Specifies the event type. For a scroll action, this property is
always set to
scroll
openai: SimpleInputMessage
Fields
- role string - The role of the message (e.g. "system", "assistant", "user")
- content string - The content of the message
openai: StaticChunkingStrategy
Fields
- maxChunkSizeTokens int - The maximum number of tokens in each chunk. The default value is
800. The minimum value is100and the maximum value is4096
- chunkOverlapTokens int - The number of tokens that overlap between chunks. The default value is
400. Note that the overlap must not exceed half ofmax_chunk_size_tokens
openai: StaticChunkingStrategyRequestParam
Customize your own chunking strategy by setting chunk size and chunk overlap
Fields
- static StaticChunkingStrategy -
- 'type "static" - Always
static
openai: StaticChunkingStrategyResponseParam
Fields
- static StaticChunkingStrategy -
- 'type "static" - Always
static
openai: SubmitToolOutputsRunRequest
Fields
- 'stream? boolean? - If
true, returns a stream of events that happen during the Run as server-sent events, terminating when the Run enters a terminal state with adata: [DONE]message
- toolOutputs SubmitToolOutputsRunRequestToolOutputs[] - A list of tools for which the outputs are being submitted
openai: SubmitToolOutputsRunRequestToolOutputs
Fields
- output? string - The output of the tool call to be submitted to continue the run
- toolCallId? string - The ID of the tool call in the
required_actionobject within the run object the output is being submitted for
openai: TextResponseFormatJsonSchema
JSON Schema response format. Used to generate structured JSON responses. Learn more about Structured Outputs
Fields
- schema ResponseFormatJsonSchemaSchema - The schema for the response format, described as a JSON Schema object. Learn how to build JSON schemas here
- name string - The name of the response format. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64
- description? string - A description of what the response format is for, used by the model to determine how to respond in the format
- 'type "json_schema" - The type of response format being defined. Always
json_schema
- strict boolean?(default false) - Whether to enable strict schema adherence when generating the output.
If set to true, the model will always follow the exact schema defined
in the
schemafield. Only a subset of JSON Schema is supported whenstrictistrue. To learn more, read the Structured Outputs guide
openai: ThreadObject
Represents a thread that contains messages
Fields
- toolResources ModifyThreadRequestToolResources? -
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- createdAt int - The Unix timestamp (in seconds) for when the thread was created
- id string - The identifier, which can be referenced in API endpoints
- 'object "thread" - The object type, which is always
thread
openai: ToggleCertificatesRequest
Fields
- certificateIds string[] -
openai: ToolChoiceFunction
Use this option to force the model to call a specific function
Fields
- name string - The name of the function to call
- 'type "function" - For function calling, the type is always
function
openai: ToolChoiceTypes
Indicates that the model should use a built-in tool to generate a response. Learn more about built-in tools
Fields
- 'type "file_search"|"web_search_preview"|"computer_use_preview"|"web_search_preview_2025_03_11" - The type of hosted tool the model should to use. Learn more about
built-in tools.
Allowed values are:
file_searchweb_search_previewcomputer_use_preview
openai: TranscriptionSegment
Fields
- 'start float - Start time of the segment in seconds
- temperature float - Temperature parameter used for generating the segment
- avgLogprob float - Average logprob of the segment. If the value is lower than -1, consider the logprobs failed
- noSpeechProb float - Probability of no speech in the segment. If the value is higher than 1.0 and the
avg_logprobis below -1, consider this segment silent
- end float - End time of the segment in seconds
- tokens int[] - Array of token IDs for the text content
- id int - Unique identifier of the segment
- text string - Text content of the segment
- seek int - Seek offset of the segment
- compressionRatio float - Compression ratio of the segment. If the value is greater than 2.4, consider the compression failed
openai: TranscriptionWord
Fields
- 'start float - Start time of the word in seconds
- end float - End time of the word in seconds
- word string - The text content of the word
openai: TruncationObject
Controls for how a thread will be truncated prior to the run. Use this to control the intial context window of the run
Fields
- lastMessages? int? - The number of most recent messages from the thread when constructing the context for the run
- 'type "auto"|"last_messages" - The truncation strategy to use for the thread. The default is
auto. If set tolast_messages, the thread will be truncated to the n most recent messages in the thread. When set toauto, messages in the middle of the thread will be dropped to fit the context length of the model,max_prompt_tokens
openai: Type
An action to type in text
Fields
- text string - The text to type
- 'type "type" (default "type") - Specifies the event type. For a type action, this property is
always set to
type
openai: UpdateVectorStoreFileAttributesRequest
Fields
- attributes VectorStoreFileAttributes? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
openai: UpdateVectorStoreRequest
Fields
- metadata? Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- expiresAfter? VectorStoreExpirationAfter -
- name? string? - The name of the vector store
openai: Upload
The Upload object can accept byte chunks in the form of Parts
Fields
- filename string - The name of the file to be uploaded
- expiresAt int - The Unix timestamp (in seconds) for when the Upload will expire
- file? OpenAIFile -
- purpose string - The intended purpose of the file. Please refer here for acceptable values
- bytes int - The intended number of bytes to be uploaded
- createdAt int - The Unix timestamp (in seconds) for when the Upload was created
- id string - The Upload unique identifier, which can be referenced in API endpoints
- status "pending"|"completed"|"cancelled"|"expired" - The status of the Upload
- 'object? "upload" - The object type, which is always "upload"
openai: UploadCertificateRequest
Fields
- name? string - An optional name for the certificate
- content string - The certificate content in PEM format
openai: UploadPart
The upload Part represents a chunk of bytes we can add to an Upload object
Fields
- uploadId string - The ID of the Upload object that this Part was added to
- createdAt int - The Unix timestamp (in seconds) for when the Part was created
- id string - The upload Part unique identifier, which can be referenced in API endpoints
- 'object "upload.part" - The object type, which is always
upload.part
openai: UrlCitationBody
A citation for a web resource used to generate a model response
Fields
- startIndex int - The index of the first character of the URL citation in the message
- endIndex int - The index of the last character of the URL citation in the message
- 'type "url_citation" (default "url_citation") - The type of the URL citation. Always
url_citation
- title string - The title of the web resource
- url string - The URL of the web resource
openai: UsageAudioSpeechesQueries
Represents the Queries record for the operation: usage-audio-speeches
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- models? string[] - Return only usage for these models
- userIds? string[] - Return only usage for these users
- apiKeyIds? string[] - Return only usage for these API keys
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id"|"user_id"|"api_key_id"|"model")[] - Group the usage data by the specified fields. Support fields include
project_id,user_id,api_key_id,modelor any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageAudioSpeechesResult
The aggregated audio speeches usage details of the specific time bucket
Fields
- characters int - The number of characters processed
- numModelRequests int - The count of requests made to the model
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- userId? string? - When
group_by=user_id, this field provides the user ID of the grouped usage result
- model? string? - When
group_by=model, this field provides the model name of the grouped usage result
- apiKeyId? string? - When
group_by=api_key_id, this field provides the API key ID of the grouped usage result
- 'object "organization.usage.audio_speeches.result" -
openai: UsageAudioTranscriptionsQueries
Represents the Queries record for the operation: usage-audio-transcriptions
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- models? string[] - Return only usage for these models
- userIds? string[] - Return only usage for these users
- apiKeyIds? string[] - Return only usage for these API keys
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id"|"user_id"|"api_key_id"|"model")[] - Group the usage data by the specified fields. Support fields include
project_id,user_id,api_key_id,modelor any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageAudioTranscriptionsResult
The aggregated audio transcriptions usage details of the specific time bucket
Fields
- seconds int - The number of seconds processed
- numModelRequests int - The count of requests made to the model
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- userId? string? - When
group_by=user_id, this field provides the user ID of the grouped usage result
- model? string? - When
group_by=model, this field provides the model name of the grouped usage result
- apiKeyId? string? - When
group_by=api_key_id, this field provides the API key ID of the grouped usage result
- 'object "organization.usage.audio_transcriptions.result" -
openai: UsageCodeInterpreterSessionsQueries
Represents the Queries record for the operation: usage-code-interpreter-sessions
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id")[] - Group the usage data by the specified fields. Support fields include
project_id
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageCodeInterpreterSessionsResult
The aggregated code interpreter sessions usage details of the specific time bucket
Fields
- numSessions? int - The number of code interpreter sessions
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- 'object "organization.usage.code_interpreter_sessions.result" -
openai: UsageCompletionsQueries
Represents the Queries record for the operation: usage-completions
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- models? string[] - Return only usage for these models
- userIds? string[] - Return only usage for these users
- apiKeyIds? string[] - Return only usage for these API keys
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- batch? boolean - If
true, return batch jobs only. Iffalse, return non-batch jobs only. By default, return both
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id"|"user_id"|"api_key_id"|"model"|"batch")[] - Group the usage data by the specified fields. Support fields include
project_id,user_id,api_key_id,model,batchor any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageCompletionsResult
The aggregated completions usage details of the specific time bucket
Fields
- numModelRequests int - The count of requests made to the model
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- userId? string? - When
group_by=user_id, this field provides the user ID of the grouped usage result
- outputAudioTokens? int - The aggregated number of audio output tokens used
- batch? boolean? - When
group_by=batch, this field tells whether the grouped usage result is batch or not
- outputTokens int - The aggregated number of text output tokens used. For customers subscribe to scale tier, this includes scale tier tokens
- model? string? - When
group_by=model, this field provides the model name of the grouped usage result
- inputCachedTokens? int - The aggregated number of text input tokens that has been cached from previous requests. For customers subscribe to scale tier, this includes scale tier tokens
- inputAudioTokens? int - The aggregated number of audio input tokens used, including cached tokens
- inputTokens int - The aggregated number of text input tokens used, including cached tokens. For customers subscribe to scale tier, this includes scale tier tokens
- apiKeyId? string? - When
group_by=api_key_id, this field provides the API key ID of the grouped usage result
- 'object "organization.usage.completions.result" -
openai: UsageCostsQueries
Represents the Queries record for the operation: usage-costs
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit int(default 7) - A limit on the number of buckets to be returned. Limit can range between 1 and 180, and the default is 7
- groupBy? ("project_id"|"line_item")[] - Group the costs by the specified fields. Support fields include
project_id,line_itemand any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1d" (default "1d") - Width of each time bucket in response. Currently only
1dis supported, default to1d
- projectIds? string[] - Return only costs for these projects
openai: UsageEmbeddingsQueries
Represents the Queries record for the operation: usage-embeddings
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- models? string[] - Return only usage for these models
- userIds? string[] - Return only usage for these users
- apiKeyIds? string[] - Return only usage for these API keys
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id"|"user_id"|"api_key_id"|"model")[] - Group the usage data by the specified fields. Support fields include
project_id,user_id,api_key_id,modelor any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageEmbeddingsResult
The aggregated embeddings usage details of the specific time bucket
Fields
- numModelRequests int - The count of requests made to the model
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- userId? string? - When
group_by=user_id, this field provides the user ID of the grouped usage result
- model? string? - When
group_by=model, this field provides the model name of the grouped usage result
- inputTokens int - The aggregated number of input tokens used
- apiKeyId? string? - When
group_by=api_key_id, this field provides the API key ID of the grouped usage result
- 'object "organization.usage.embeddings.result" -
openai: UsageImagesQueries
Represents the Queries record for the operation: usage-images
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- models? string[] - Return only usage for these models
- sources? ("image.generation"|"image.edit"|"image.variation")[] - Return only usages for these sources. Possible values are
image.generation,image.edit,image.variationor any combination of them
- sizes? ("256x256"|"512x512"|"1024x1024"|"1792x1792"|"1024x1792")[] - Return only usages for these image sizes. Possible values are
256x256,512x512,1024x1024,1792x1792,1024x1792or any combination of them
- userIds? string[] - Return only usage for these users
- apiKeyIds? string[] - Return only usage for these API keys
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id"|"user_id"|"api_key_id"|"model"|"size"|"source")[] - Group the usage data by the specified fields. Support fields include
project_id,user_id,api_key_id,model,size,sourceor any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageImagesResult
The aggregated images usage details of the specific time bucket
Fields
- images int - The number of images processed
- numModelRequests int - The count of requests made to the model
- size? string? - When
group_by=size, this field provides the image size of the grouped usage result
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- userId? string? - When
group_by=user_id, this field provides the user ID of the grouped usage result
- model? string? - When
group_by=model, this field provides the model name of the grouped usage result
- 'source? string? - When
group_by=source, this field provides the source of the grouped usage result, possible values areimage.generation,image.edit,image.variation
- apiKeyId? string? - When
group_by=api_key_id, this field provides the API key ID of the grouped usage result
- 'object "organization.usage.images.result" -
openai: UsageModerationsQueries
Represents the Queries record for the operation: usage-moderations
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- models? string[] - Return only usage for these models
- userIds? string[] - Return only usage for these users
- apiKeyIds? string[] - Return only usage for these API keys
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id"|"user_id"|"api_key_id"|"model")[] - Group the usage data by the specified fields. Support fields include
project_id,user_id,api_key_id,modelor any combination of them
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageModerationsResult
The aggregated moderations usage details of the specific time bucket
Fields
- numModelRequests int - The count of requests made to the model
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- userId? string? - When
group_by=user_id, this field provides the user ID of the grouped usage result
- model? string? - When
group_by=model, this field provides the model name of the grouped usage result
- inputTokens int - The aggregated number of input tokens used
- apiKeyId? string? - When
group_by=api_key_id, this field provides the API key ID of the grouped usage result
- 'object "organization.usage.moderations.result" -
openai: UsageResponse
Fields
- nextPage string -
- data UsageTimeBucket[] -
- hasMore boolean -
- 'object "page" -
openai: UsageTimeBucket
Fields
- result UsageTimeBucketResult[] -
- startTime int -
- endTime int -
- 'object "bucket" -
openai: UsageVectorStoresQueries
Represents the Queries record for the operation: usage-vector-stores
Fields
- startTime int - Start time (Unix seconds) of the query time range, inclusive
- endTime? int - End time (Unix seconds) of the query time range, exclusive
- 'limit? int - Specifies the number of buckets to return.
bucket_width=1d: default: 7, max: 31bucket_width=1h: default: 24, max: 168bucket_width=1m: default: 60, max: 1440
- groupBy? ("project_id")[] - Group the usage data by the specified fields. Support fields include
project_id
- page? string - A cursor for use in pagination. Corresponding to the
next_pagefield from the previous response
- bucketWidth "1m"|"1h"|"1d" (default "1d") - Width of each time bucket in response. Currently
1m,1hand1dare supported, default to1d
- projectIds? string[] - Return only usage for these projects
openai: UsageVectorStoresResult
The aggregated vector stores usage details of the specific time bucket
Fields
- projectId? string? - When
group_by=project_id, this field provides the project ID of the grouped usage result
- usageBytes int - The vector stores usage in bytes
- 'object "organization.usage.vector_stores.result" -
openai: User
Represents an individual user within an organization
Fields
- addedAt int - The Unix timestamp (in seconds) of when the user was added
- role "owner"|"reader" -
ownerorreader
- name string - The name of the user
- id string - The identifier, which can be referenced in API endpoints
- email string - The email address of the user
- 'object "organization.user" - The object type, which is always
organization.user
openai: UserDeleteResponse
Fields
- deleted boolean -
- id string -
- 'object "organization.user.deleted" -
openai: UserListResponse
Fields
- firstId string -
- data User[] -
- lastId string -
- hasMore boolean -
- 'object "list" -
openai: UserRoleUpdateRequest
Fields
- role "owner"|"reader" -
ownerorreader
openai: VectorStoreExpirationAfter
The expiration policy for a vector store
Fields
- anchor "last_active_at" - Anchor timestamp after which the expiration policy applies. Supported anchors:
last_active_at
- days int - The number of days after the anchor time that the vector store will expire
openai: VectorStoreFileAttributes
Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
openai: VectorStoreFileBatchObject
A batch of files attached to a vector store
Fields
- fileCounts VectorStoreFileBatchObjectFileCounts -
- createdAt int - The Unix timestamp (in seconds) for when the vector store files batch was created
- id string - The identifier, which can be referenced in API endpoints
- 'object "vector_store.files_batch" - The object type, which is always
vector_store.file_batch
- vectorStoreId string - The ID of the vector store that the File is attached to
- status "in_progress"|"completed"|"cancelled"|"failed" - The status of the vector store files batch, which can be either
in_progress,completed,cancelledorfailed
openai: VectorStoreFileBatchObjectFileCounts
Fields
- inProgress int - The number of files that are currently being processed
- total int - The total number of files
- cancelled int - The number of files that where cancelled
- completed int - The number of files that have been processed
- failed int - The number of files that have failed to process
openai: VectorStoreFileContentResponse
Represents the parsed content of a vector store file
Fields
- nextPage string? - The token for the next page, if any
- data VectorStoreFileContentResponseData[] - Parsed content of the file
- hasMore boolean - Indicates if there are more content pages to fetch
- 'object "vector_store.file_content.page" - The object type, which is always
vector_store.file_content.page
openai: VectorStoreFileContentResponseData
Fields
- text? string - The text content
- 'type? string - The content type (currently only
"text")
openai: VectorStoreFileObject
A list of files attached to a vector store
Fields
- chunkingStrategy? StaticChunkingStrategyResponseParam|OtherChunkingStrategyResponseParam - The strategy used to chunk the file
- usageBytes int - The total vector store usage in bytes. Note that this may be different from the original file size
- createdAt int - The Unix timestamp (in seconds) for when the vector store file was created
- attributes? VectorStoreFileAttributes? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
- id string - The identifier, which can be referenced in API endpoints
- lastError VectorStoreFileObjectLastError? -
- 'object "vector_store.file" - The object type, which is always
vector_store.file
- vectorStoreId string - The ID of the vector store that the File is attached to
- status "in_progress"|"completed"|"cancelled"|"failed" - The status of the vector store file, which can be either
in_progress,completed,cancelled, orfailed. The statuscompletedindicates that the vector store file is ready for use
openai: VectorStoreFileObjectLastError
The last error associated with this vector store file. Will be null if there are no errors
Fields
- code "server_error"|"unsupported_file"|"invalid_file" - One of
server_errororrate_limit_exceeded
- message string - A human-readable description of the error
openai: VectorStoreObject
A vector store is a collection of processed files can be used by the file_search tool
Fields
- fileCounts VectorStoreObjectFileCounts -
- metadata Metadata? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters
- expiresAt? int? - The Unix timestamp (in seconds) for when the vector store will expire
- expiresAfter? VectorStoreExpirationAfter -
- lastActiveAt int? - The Unix timestamp (in seconds) for when the vector store was last active
- usageBytes int - The total number of bytes used by the files in the vector store
- name string - The name of the vector store
- createdAt int - The Unix timestamp (in seconds) for when the vector store was created
- id string - The identifier, which can be referenced in API endpoints
- 'object "vector_store" - The object type, which is always
vector_store
- status "expired"|"in_progress"|"completed" - The status of the vector store, which can be either
expired,in_progress, orcompleted. A status ofcompletedindicates that the vector store is ready for use
openai: VectorStoreObjectFileCounts
Fields
- inProgress int - The number of files that are currently being processed
- total int - The total number of files
- cancelled int - The number of files that were cancelled
- completed int - The number of files that have been successfully processed
- failed int - The number of files that have failed to process
openai: VectorStoreSearchRequest
Fields
- maxNumResults int(default 10) - The maximum number of results to return. This number should be between 1 and 50 inclusive
- rankingOptions? VectorStoreSearchRequestRankingOptions -
- query string|QueryItemsString[] - A query string for a search
- rewriteQuery boolean(default false) - Whether to rewrite the natural language query for vector search
- filters? ComparisonFilter|CompoundFilter - A filter to apply based on file attributes
openai: VectorStoreSearchRequestRankingOptions
Ranking options for search
Fields
- scoreThreshold decimal(default 0) -
- ranker "auto"|"default-2024-11-15" (default "auto") -
openai: VectorStoreSearchResultContentObject
Fields
- text string - The text content returned from search
- 'type "text" - The type of content
openai: VectorStoreSearchResultItem
Fields
- score decimal - The similarity score for the result
- filename string - The name of the vector store file
- fileId string - The ID of the vector store file
- attributes VectorStoreFileAttributes? - Set of 16 key-value pairs that can be attached to an object. This can be useful for storing additional information about the object in a structured format, and querying for objects via API or the dashboard. Keys are strings with a maximum length of 64 characters. Values are strings with a maximum length of 512 characters, booleans, or numbers
- content VectorStoreSearchResultContentObject[] - Content chunks from the file
openai: VectorStoreSearchResultsPage
Fields
- nextPage string? - The token for the next page, if any
- data VectorStoreSearchResultItem[] - The list of search result items
- hasMore boolean - Indicates if there are more results to fetch
- searchQuery VectorStoreSearchResultsPageSearchqueryItemsString[] -
- 'object "vector_store.search_results.page" - The object type, which is always
vector_store.search_results.page
openai: Wait
A wait action
Fields
- 'type "wait" (default "wait") - Specifies the event type. For a wait action, this property is
always set to
wait
openai: WebSearch
This tool searches the web for relevant results to use in a response. Learn more about the web search tool
Fields
- searchContextSize? WebSearchContextSize -
- userLocation? WebSearchUserLocation? -
openai: WebSearchLocation
Approximate location parameters for the search
Fields
- country? string - The two-letter
ISO country code of the user,
e.g.
US
- city? string - Free text input for the city of the user, e.g.
San Francisco
- timezone? string - The IANA timezone
of the user, e.g.
America/Los_Angeles
- region? string - Free text input for the region of the user, e.g.
California
openai: WebSearchPreviewTool
This tool searches the web for relevant results to use in a response. Learn more about the web search tool
Fields
- searchContextSize? "low"|"medium"|"high" - High level guidance for the amount of context window space to use for the search. One of
low,medium, orhigh.mediumis the default
- userLocation? anydata -
- 'type "web_search_preview"|"web_search_preview_2025_03_11" (default "web_search_preview") - The type of the web search tool. One of
web_search_previeworweb_search_preview_2025_03_11
openai: WebSearchToolCall
The results of a web search tool call. See the web search guide for more information
Fields
- id string - The unique ID of the web search tool call
- 'type "web_search_call" - The type of the web search tool call. Always
web_search_call
- status "in_progress"|"searching"|"completed"|"failed" - The status of the web search tool call
openai: WebSearchUserLocation
Approximate location parameters for the search
Fields
- approximate WebSearchLocation - Approximate location parameters for the search
- 'type "approximate" - The type of location approximation. Always
approximate
Union types
openai: AssistantsApiResponseFormatOption
AssistantsApiResponseFormatOption
Specifies the format that the model must output. Compatible with GPT-4o, GPT-4 Turbo, and all GPT-3.5 Turbo models since gpt-3.5-turbo-1106.
Setting to { "type": "json_schema", "json_schema": {...} } enables Structured Outputs which ensures the model will match your supplied JSON schema. Learn more in the Structured Outputs guide.
Setting to { "type": "json_object" } enables JSON mode, which ensures the message the model generates is valid JSON.
Important: when using JSON mode, you must also instruct the model to produce JSON yourself via a system or user message. Without this, the model may generate an unending stream of whitespace until the generation reaches the token limit, resulting in a long-running and seemingly "stuck" request. Also note that the message content may be partially cut off if finish_reason="length", which indicates the generation exceeded max_tokens or the conversation exceeded the max context length
openai: InputContent
InputContent
openai: CreateMessageRequestTools
CreateMessageRequestTools
openai: ChatCompletionRequestAssistantMessageContentPart
ChatCompletionRequestAssistantMessageContentPart
openai: InlineResponse2001
InlineResponse2001
openai: RunStepDetailsToolCallsCodeObjectCodeInterpreterOutputs
RunStepDetailsToolCallsCodeObjectCodeInterpreterOutputs
openai: ToolChoiceOptions
ToolChoiceOptions
Controls which (if any) tool is called by the model.
none means the model will not call any tool and instead generates a message.
auto means the model can pick between generating a message or calling one or
more tools.
required means the model must call one or more tools
openai: StopConfiguration
StopConfiguration
Not supported with latest reasoning models o3 and o4-mini.
Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence
openai: InputItem
InputItem
openai: OutputItem
OutputItem
openai: ChatCompletionRequestMessage
ChatCompletionRequestMessage
openai: Annotation
Annotation
openai: MessageContentTextObjectTextAnnotations
MessageContentTextObjectTextAnnotations
openai: ChatCompletionRequestUserMessageContentPart
ChatCompletionRequestUserMessageContentPart
openai: Tool
Tool
openai: ModelIdsSharedModelIdsSharedAnyOf12
ModelIdsSharedModelIdsSharedAnyOf12
openai: MessageObjectContent
MessageObjectContent
openai: InlineResponse200
InlineResponse200
openai: WebSearchContextSize
WebSearchContextSize
High level guidance for the amount of context window space to use for the
search. One of low, medium, or high. medium is the default
openai: VoiceIdsSharedVoiceIdsSharedAnyOf12
VoiceIdsSharedVoiceIdsSharedAnyOf12
openai: AssistantsApiToolChoiceOptionOneOf1
AssistantsApiToolChoiceOptionOneOf1
none means the model will not call any tools and instead generates a message. auto means the model can pick between generating a message or calling one or more tools. required means the model must call one or more tools before responding to the user
openai: ChatCompletionToolChoiceOption
ChatCompletionToolChoiceOption
Controls which (if any) tool is called by the model.
none means the model will not call any tool and instead generates a message.
auto means the model can pick between generating a message or calling one or more tools.
required means the model must call one or more tools.
Specifying a particular tool via {"type": "function", "function": {"name": "my_function"}} forces the model to call that tool.
none is the default when no tools are present. auto is the default if tools are present
openai: EvalTestingCriteria
EvalTestingCriteria
openai: ServiceTier
ServiceTier
Specifies the latency tier to use for processing the request. This parameter is relevant for customers subscribed to the scale tier service:
- If set to 'auto', and the Project is Scale tier enabled, the system will utilize scale tier credits until they are exhausted.
- If set to 'auto', and the Project is not Scale tier enabled, the request will be processed using the default service tier with a lower uptime SLA and no latency guarentee.
- If set to 'default', the request will be processed using the default service tier with a lower uptime SLA and no latency guarentee.
- If set to 'flex', the request will be processed with the Flex Processing service tier. Learn more.
- When not set, the default behavior is 'auto'.
When this parameter is set, the response body will include the service_tier utilized
openai: RunStepDetailsToolCallsObjectToolCalls
RunStepDetailsToolCallsObjectToolCalls
openai: ItemResource
ItemResource
Content item used to generate a response
openai: ChatCompletionToolChoiceOptionOneOf1
ChatCompletionToolChoiceOptionOneOf1
none means the model will not call any tool and instead generates a message. auto means the model can pick between generating a message or calling one or more tools. required means the model must call one or more tools
openai: Includable
Includable
Specify additional output data to include in the model response. Currently supported values are:
file_search_call.results: Include the search results of the file search tool call.message.input_image.image_url: Include image urls from the input message.computer_call_output.output.image_url: Include image urls from the computer call output
openai: AssistantsApiToolChoiceOption
AssistantsApiToolChoiceOption
Controls which (if any) tool is called by the model.
none means the model will not call any tools and instead generates a message.
auto is the default value and means the model can pick between generating a message or calling one or more tools.
required means the model must call one or more tools before responding to the user.
Specifying a particular tool like {"type": "file_search"} or {"type": "function", "function": {"name": "my_function"}} forces the model to call that tool
openai: AssistantSupportedModels
AssistantSupportedModels
openai: CreateEvalRequestTestingCriteria
CreateEvalRequestTestingCriteria
openai: TextResponseFormatConfiguration
TextResponseFormatConfiguration
An object specifying the format that the model must output.
Configuring { "type": "json_schema" } enables Structured Outputs,
which ensures the model will match your supplied JSON schema. Learn more in the
Structured Outputs guide.
The default format is { "type": "text" } with no additional options.
Not recommended for gpt-4o and newer models:
Setting to { "type": "json_object" } enables the older JSON mode, which
ensures the message the model generates is valid JSON. Using json_schema
is preferred for models that support it
openai: FileSearchRanker
FileSearchRanker
The ranker to use for the file search. If not specified will use the auto ranker
openai: Item
Item
Content item used to generate a response
openai: AudioResponseFormat
AudioResponseFormat
The format of the output, in one of these options: json, text, srt, verbose_json, or vtt. For gpt-4o-transcribe and gpt-4o-mini-transcribe, the only supported format is json
openai: ComputerAction
ComputerAction
openai: VoiceIdsShared
VoiceIdsShared
openai: ModelIdsResponses
ModelIdsResponses
openai: ChunkingStrategyRequestParam
ChunkingStrategyRequestParam
The chunking strategy used to chunk the file(s). If not set, will use the auto strategy
openai: UsageTimeBucketResult
UsageTimeBucketResult
openai: ResponsesOnlyModel
ResponsesOnlyModel
openai: AssistantObjectTools
AssistantObjectTools
openai: ReasoningEffort
ReasoningEffort
o-series models only
Constrains effort on reasoning for
reasoning models.
Currently supported values are low, medium, and high. Reducing
reasoning effort can result in faster responses and fewer tokens used
on reasoning in a response
openai: Filters
Filters
openai: OutputContent
OutputContent
openai: ModelIdsShared
ModelIdsShared
openai: ResponseErrorCode
ResponseErrorCode
The error code for the response
openai: CreateEvalItem
CreateEvalItem
A chat message that makes up the prompt or context. May include variable references to the "item" namespace, ie {{item.name}}
openai: AuditLogEventType
AuditLogEventType
The event type
Array types
openai: ResponseModalities
ResponseModalities
Output types that you would like the model to generate. Most models are capable of generating text, which is the default:
["text"]
The gpt-4o-audio-preview model can also be used to
generate audio. To request that this model generate
both text and audio responses, you can use:
["text", "audio"]
openai: InputItemsArray
InputItemsArray
openai: ChatCompletionMessageToolCalls
ChatCompletionMessageToolCalls
The tool calls generated by the model, such as function calls
openai: PromptItemsArray
PromptItemsArray
openai: StopConfigurationStopConfigurationOneOf12
StopConfigurationStopConfigurationOneOf12
openai: InputMessageContentList
InputMessageContentList
A list of one or many input items to the model, containing different content types
Anydata types
openai: CreateThreadRequestToolResourcesFileSearch
CreateThreadRequestToolResourcesFileSearch
openai: CreateAssistantRequestToolResourcesFileSearch
CreateAssistantRequestToolResourcesFileSearch
String types
openai: QueryItemsString
QueryItemsString
openai: ModelIdsSharedAnyOf1
ModelIdsSharedAnyOf1
openai: VectorStoreSearchResultsPageSearchqueryItemsString
VectorStoreSearchResultsPageSearchqueryItemsString
openai: StopConfigurationOneOf1
StopConfigurationOneOf1
openai: VoiceIdsSharedAnyOf1
VoiceIdsSharedAnyOf1
Simple name reference types
openai: CreateModelResponseProperties
CreateModelResponseProperties
openai: CompoundFilterFilters
CompoundFilterFilters
openai: ChatCompletionRequestSystemMessageContentPart
ChatCompletionRequestSystemMessageContentPart
openai: ChatCompletionRequestToolMessageContentPart
ChatCompletionRequestToolMessageContentPart
openai: FineTuningJobIntegrations
FineTuningJobIntegrations
Boolean types
openai: ParallelToolCalls
ParallelToolCalls
Whether to enable parallel function calling during tool use
Import
import ballerinax/openai;Other versions
1.0.0