Module openai.chat

ballerinax/openai.chat Ballerina library
Overview
OpenAI, an AI research organization focused on creating friendly AI for humanity, offers the OpenAI API to access its powerful AI models for tasks like natural language processing and image generation.
The ballarinax/openai.chat package offers functionality to connect and interact with chat completion related endpoints of OpenAI REST API v1 Enabling seamless interaction with the advanced GPT-4 models developed by OpenAI for diverse conversational and text generation tasks.
Setup guide
To use the OpenAI Connector, you must have access to the OpenAI API through a OpenAI Platform account and a project under it. If you do not have a OpenAI Platform account, you can sign up for one here.
Create a OpenAI API Key
-
Open the OpenAI Platform Dashboard.
-
Navigate to Dashboard -> API keys.
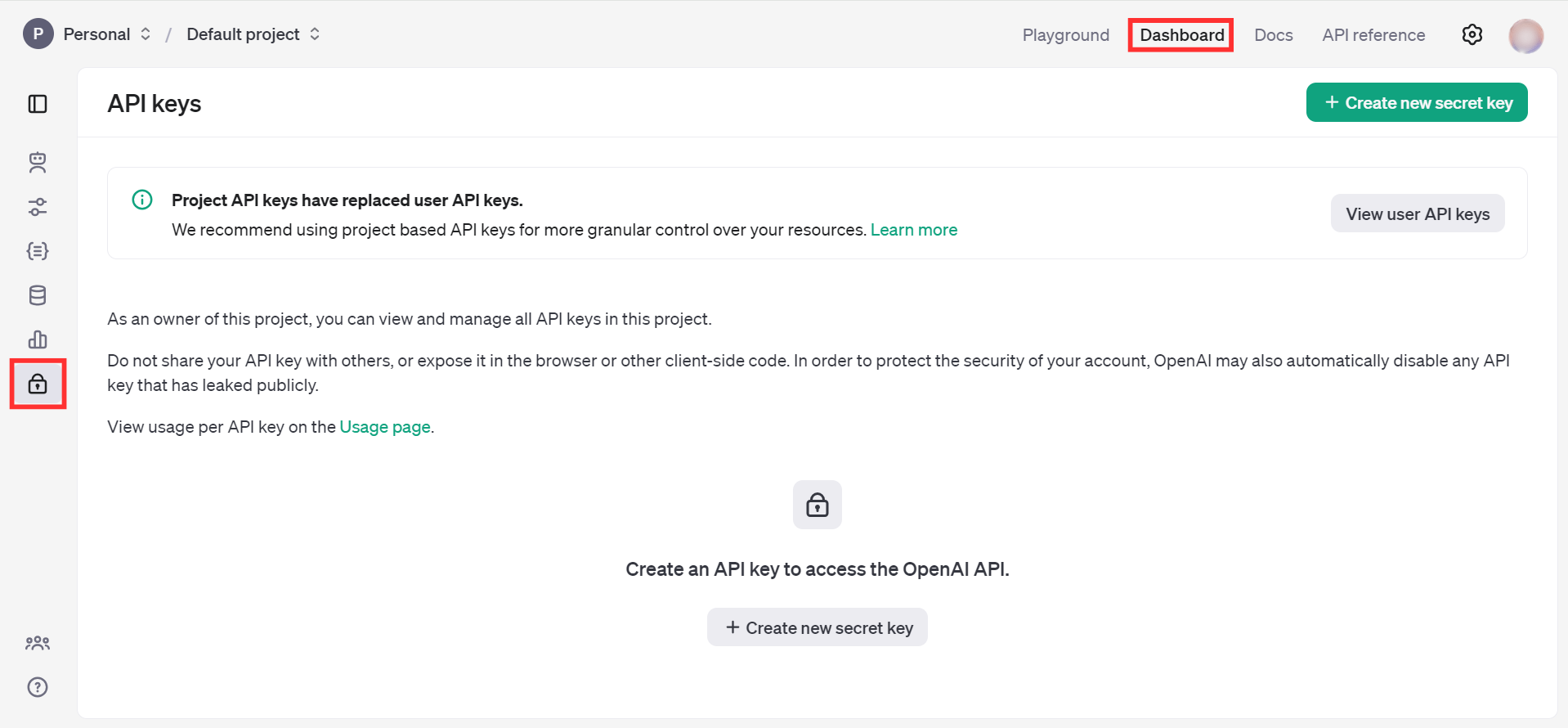
-
Click on the "Create new secret key" button.
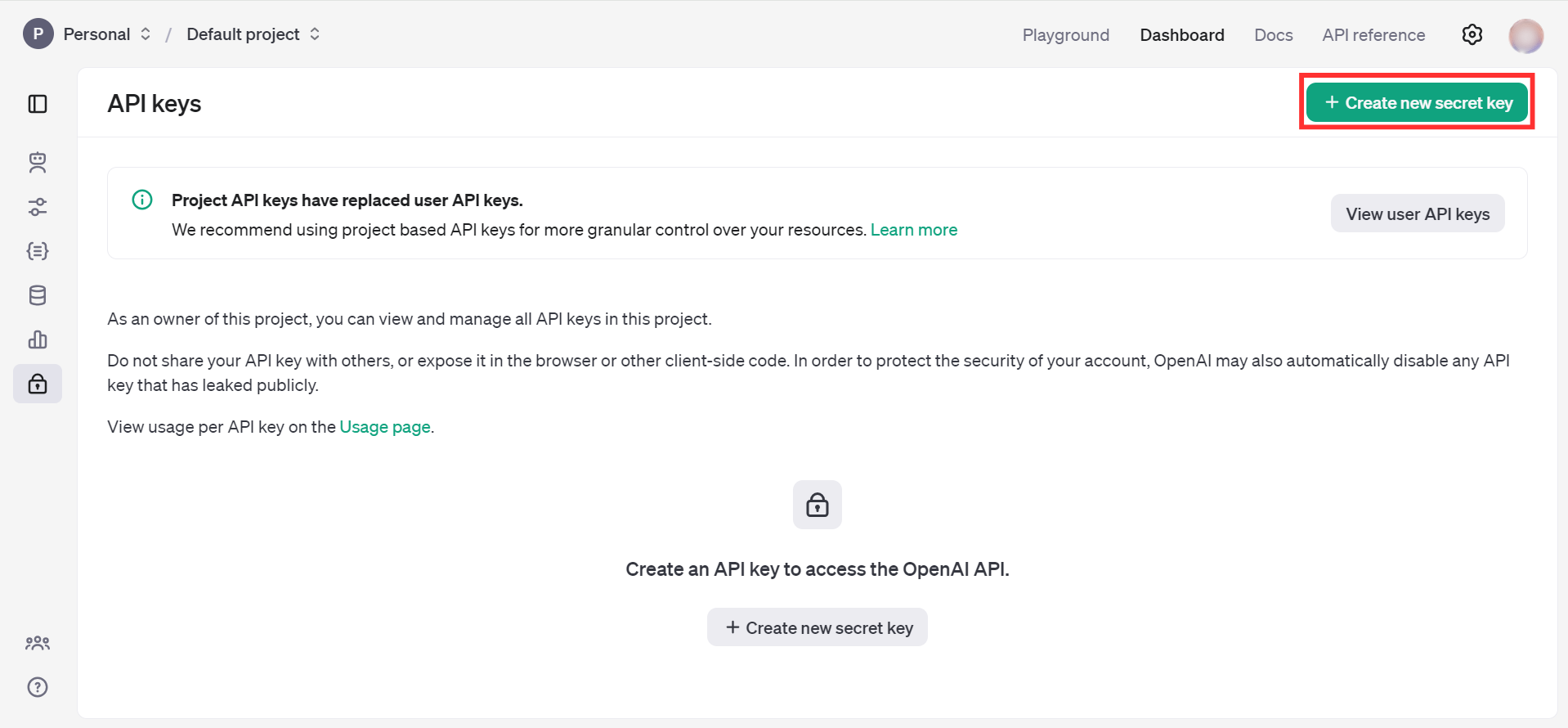
-
Fill the details and click on Create secret key.
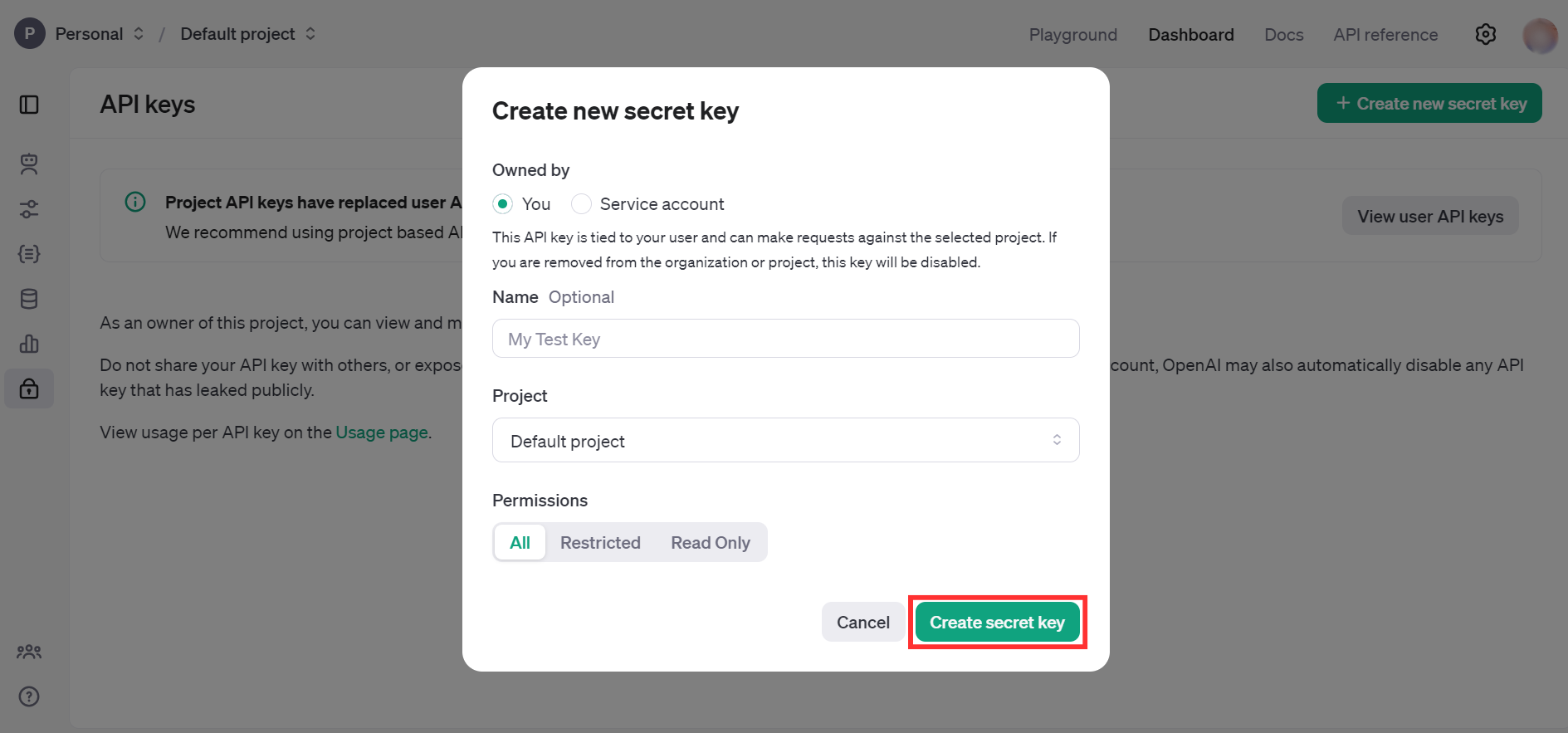
-
Store the API key securely to use in your application.
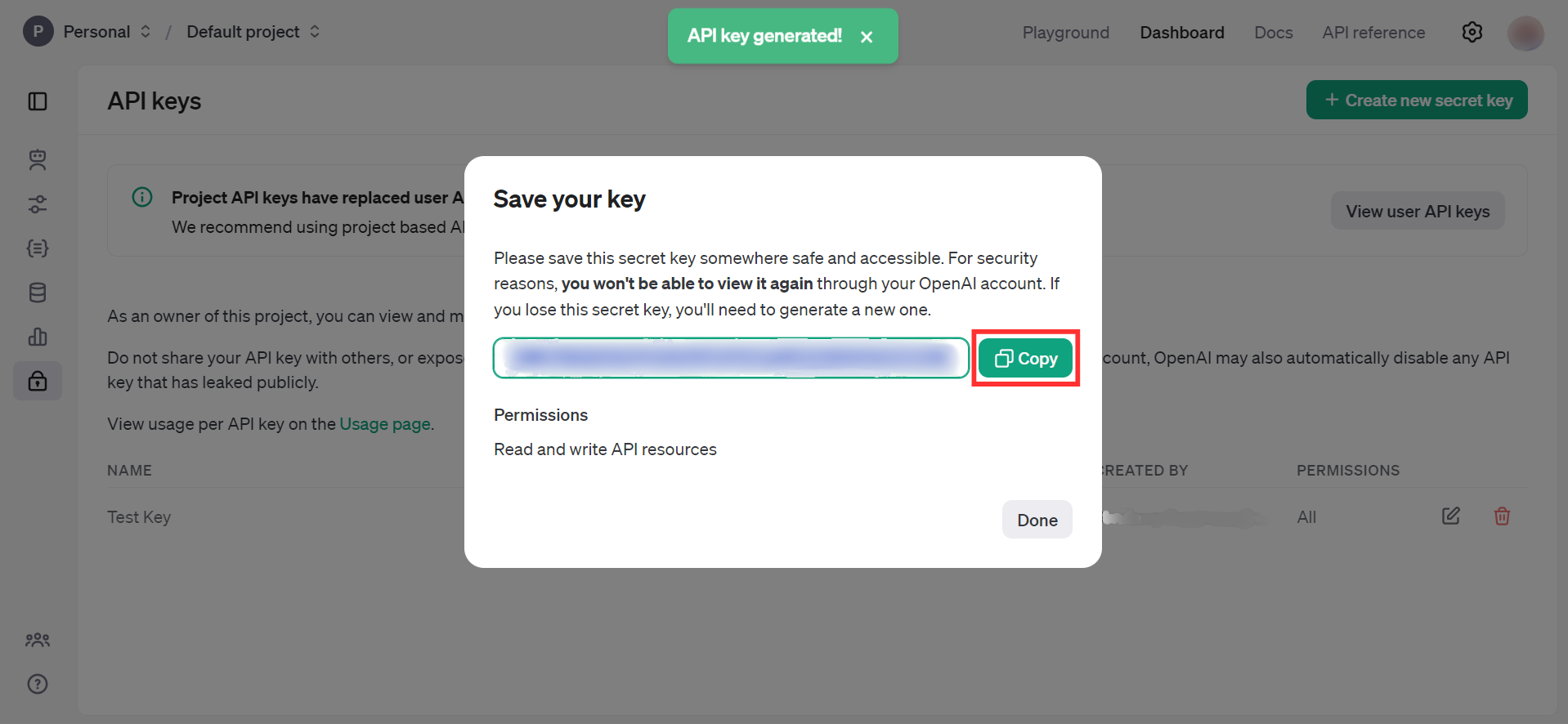
Quickstart
To use the OpenAI Chat connector in your Ballerina application, update the .bal file as follows:
Step 1: Import the module
Import the ballerinax/openai.chat module.
import ballerinax/openai.chat;
Step 2: Create a new connector instance
Create a chat:Client with the obtained API Key and initialize the connector.
configurable string token = ?; final chat:Client openAIChat = check new({ auth: { token } });
Step 3: Invoke the connector operation
Now, you can utilize available connector operations.
Generate a response for given message
public function main() returns error? { // Create a chat completion request. chat:CreateChatCompletionRequest request = { model: "gpt-4o-mini", messages: [{ "role": "user", "content": "What is Ballerina programming language?" }] }; chat:CreateChatCompletionResponse response = check openAIChat->/chat/completions.post(request); }
Step 4: Run the Ballerina application
bal run
Examples
The OpenAI Chat connector provides practical examples illustrating usage in various scenarios. Explore these examples, covering the following use cases:
- CLI assistant - Execute the user's task description by generating and running the appropriate command in the command line interface of their selected operating system.
- Image to markdown document converter - Generate detailed markdown documentation based on the image content.
Clients
openai.chat: Client
The OpenAI REST API. Please see https://platform.openai.com/docs/api-reference for more details.
Constructor
Gets invoked to initialize the connector.
init (ConnectionConfig config, string serviceUrl)- config ConnectionConfig - The configurations to be used when initializing the
connector
- serviceUrl string "https://api.openai.com/v1" - URL of the target service
post chat/completions
function post chat/completions(CreateChatCompletionRequest payload, map<string|string[]> headers) returns CreateChatCompletionResponse|errorCreates a model response for the given chat conversation. Learn more in the text generation, vision, and audio guides.
Parameters
- payload CreateChatCompletionRequest -
Return Type
Records
openai.chat: AssistantsNamedToolChoice_function
Fields
- name string - The name of the function to call.
openai.chat: ChatCompletionFunctionCallOption
Specifying a particular function via {"name": "my_function"} forces the model to call that function.
Fields
- name string - The name of the function to call.
openai.chat: ChatCompletionFunctions
Fields
- description? string - A description of what the function does, used by the model to choose when and how to call the function.
- name string - The name of the function to be called. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64.
- parameters? FunctionParameters -
openai.chat: ChatCompletionMessageToolCall
Fields
- id string - The ID of the tool call.
- 'type "function" - The type of the tool. Currently, only
functionis supported.
- 'function ChatCompletionMessageToolCall_function -
openai.chat: ChatCompletionMessageToolCall_function
The function that the model called.
Fields
- name string - The name of the function to call.
- arguments string - The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function.
openai.chat: ChatCompletionNamedToolChoice
Specifies a tool the model should use. Use to force the model to call a specific function.
Fields
- 'type "function" - The type of the tool. Currently, only
functionis supported.
- 'function AssistantsNamedToolChoice_function -
openai.chat: ChatCompletionRequestAssistantMessage
Fields
- content? string|ChatCompletionRequestAssistantMessageContentPart[]? - The contents of the assistant message. Required unless
tool_callsorfunction_callis specified.
- refusal? string? - The refusal message by the assistant.
- role "assistant" - The role of the messages author, in this case
assistant.
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role.
- tool_calls? ChatCompletionMessageToolCalls -
- function_call? ChatCompletionRequestAssistantMessage_function_call? -
openai.chat: ChatCompletionRequestAssistantMessage_audio
Data about a previous audio response from the model. Learn more.
Fields
- id string - Unique identifier for a previous audio response from the model.
openai.chat: ChatCompletionRequestAssistantMessage_function_call
Deprecated and replaced by tool_calls. The name and arguments of a function that should be called, as generated by the model.
Fields
- arguments string - The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function.
- name string - The name of the function to call.
Deprecated
openai.chat: ChatCompletionRequestFunctionMessage
Fields
- role "function" - The role of the messages author, in this case
function.
- content string? - The contents of the function message.
- name string - The name of the function to call.
openai.chat: ChatCompletionRequestMessageContentPartAudio
Learn about audio inputs.
Fields
- 'type "input_audio" - The type of the content part. Always
input_audio.
- input_audio ChatCompletionRequestMessageContentPartAudio_input_audio - The type of the content part. Always
input_audio.
openai.chat: ChatCompletionRequestMessageContentPartAudio_input_audio
Fields
- data string - Base64 encoded audio data.
- format "wav"|"mp3" - The format of the encoded audio data. Currently supports "wav" and "mp3".
openai.chat: ChatCompletionRequestMessageContentPartImage
Learn about image inputs.
Fields
- 'type "image_url" - The type of the content part.
- image_url ChatCompletionRequestMessageContentPartImage_image_url - The type of the content part. Always
image_url.
openai.chat: ChatCompletionRequestMessageContentPartImage_image_url
Fields
- url string - Either a URL of the image or the base64 encoded image data.
- detail "auto"|"low"|"high" (default "auto") - Specifies the detail level of the image. Learn more in the Vision guide.
openai.chat: ChatCompletionRequestMessageContentPartRefusal
Fields
- 'type "refusal" - The type of the content part.
- refusal string - The refusal message generated by the model.
openai.chat: ChatCompletionRequestMessageContentPartText
Learn about text inputs.
Fields
- 'type "text" - The type of the content part.
- text string - The text content.
openai.chat: ChatCompletionRequestSystemMessage
Fields
- content string|ChatCompletionRequestSystemMessageContentPart[] - The contents of the system message.
- role "system" - The role of the messages author, in this case
system.
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role.
openai.chat: ChatCompletionRequestToolMessage
Fields
- role "tool" - The role of the messages author, in this case
tool.
- content string|ChatCompletionRequestToolMessageContentPart[] - The contents of the tool message.
- tool_call_id string - Tool call that this message is responding to.
openai.chat: ChatCompletionRequestUserMessage
Fields
- content string|ChatCompletionRequestUserMessageContentPart[] - The contents of the user message.
- role "user" - The role of the messages author, in this case
user.
- name? string - An optional name for the participant. Provides the model information to differentiate between participants of the same role.
openai.chat: ChatCompletionResponseMessage
A chat completion message generated by the model.
Fields
- content string? - The contents of the message.
- refusal string? - The refusal message generated by the model.
- tool_calls? ChatCompletionMessageToolCalls - The tool calls generated by the model, such as function calls.
- role "assistant" - The role of the author of this message.
- function_call? ChatCompletionResponseMessage_function_call - Deprecated and replaced by
tool_calls. The name and arguments of a function that should be called, as generated by the model.
- audio? ChatCompletionResponseMessage_audio? - If the audio output modality is requested, this object contains data about the audio response from the model.
openai.chat: ChatCompletionResponseMessage_audio
If the audio output modality is requested, this object contains data about the audio response from the model. Learn more.
Fields
- id string - Unique identifier for this audio response.
- expires_at int - The Unix timestamp (in seconds) for when this audio response will no longer be accessible on the server for use in multi-turn conversations.
- data string - Base64 encoded audio bytes generated by the model, in the format specified in the request.
- transcript string - Transcript of the audio generated by the model.
openai.chat: ChatCompletionResponseMessage_function_call
Deprecated and replaced by tool_calls. The name and arguments of a function that should be called, as generated by the model.
Fields
- arguments string - The arguments to call the function with, as generated by the model in JSON format. Note that the model does not always generate valid JSON, and may hallucinate parameters not defined by your function schema. Validate the arguments in your code before calling your function.
- name string - The name of the function to call.
Deprecated
openai.chat: ChatCompletionStreamOptions
Options for streaming response. Only set this when you set stream: true.
Fields
- include_usage? boolean - If set, an additional chunk will be streamed before the
data: [DONE]message. Theusagefield on this chunk shows the token usage statistics for the entire request, and thechoicesfield will always be an empty array. All other chunks will also include ausagefield, but with a null value.
openai.chat: ChatCompletionTokenLogprob
Fields
- token string - The token.
- logprob decimal - The log probability of this token, if it is within the top 20 most likely tokens. Otherwise, the value
-9999.0is used to signify that the token is very unlikely.
- bytes int[]? - A list of integers representing the UTF-8 bytes representation of the token. Useful in instances where characters are represented by multiple tokens and their byte representations must be combined to generate the correct text representation. Can be
nullif there is no bytes representation for the token.
- top_logprobs ChatCompletionTokenLogprob_top_logprobs[] - List of the most likely tokens and their log probability, at this token position. In rare cases, there may be fewer than the number of requested
top_logprobsreturned.
openai.chat: ChatCompletionTokenLogprob_top_logprobs
Fields
- token string - The token.
- logprob decimal - The log probability of this token, if it is within the top 20 most likely tokens. Otherwise, the value
-9999.0is used to signify that the token is very unlikely.
- bytes int[]? - A list of integers representing the UTF-8 bytes representation of the token. Useful in instances where characters are represented by multiple tokens and their byte representations must be combined to generate the correct text representation. Can be
nullif there is no bytes representation for the token.
openai.chat: ChatCompletionTool
Fields
- 'type "function" - The type of the tool. Currently, only
functionis supported.
- 'function FunctionObject -
openai.chat: ClientHttp1Settings
Provides settings related to HTTP/1.x protocol.
Fields
- keepAlive KeepAlive(default http:KEEPALIVE_AUTO) - Specifies whether to reuse a connection for multiple requests
- chunking Chunking(default http:CHUNKING_AUTO) - The chunking behaviour of the request
- proxy? ProxyConfig - Proxy server related options
openai.chat: CompletionUsage
Usage statistics for the completion request.
Fields
- completion_tokens int - Number of tokens in the generated completion.
- prompt_tokens int - Number of tokens in the prompt.
- total_tokens int - Total number of tokens used in the request (prompt + completion).
- completion_tokens_details? CompletionUsage_completion_tokens_details - Breakdown of tokens used in the completion.
- prompt_tokens_details? CompletionUsage_prompt_tokens_details - Breakdown of tokens used in the prompt.
openai.chat: CompletionUsage_completion_tokens_details
Breakdown of tokens used in a completion.
Fields
- accepted_prediction_tokens? int - When using Predicted Outputs, the number of tokens in the prediction that appeared in the completion.
- audio_tokens? int - Audio input tokens generated by the model.
- reasoning_tokens? int - Tokens generated by the model for reasoning.
- rejected_prediction_tokens? int - When using Predicted Outputs, the number of tokens in the prediction that did not appear in the completion. However, like reasoning tokens, these tokens are still counted in the total completion tokens for purposes of billing, output, and context window limits.
openai.chat: CompletionUsage_prompt_tokens_details
Breakdown of tokens used in the prompt.
Fields
- audio_tokens? int - Audio input tokens present in the prompt.
- cached_tokens? int - Cached tokens present in the prompt.
openai.chat: ConnectionConfig
Provides a set of configurations for controlling the behaviours when communicating with a remote HTTP endpoint.
Fields
- auth BearerTokenConfig - Configurations related to client authentication
- httpVersion HttpVersion(default http:HTTP_2_0) - The HTTP version understood by the client
- http1Settings? ClientHttp1Settings - Configurations related to HTTP/1.x protocol
- http2Settings? ClientHttp2Settings - Configurations related to HTTP/2 protocol
- timeout decimal(default 60) - The maximum time to wait (in seconds) for a response before closing the connection
- forwarded string(default "disable") - The choice of setting
forwarded/x-forwardedheader
- poolConfig? PoolConfiguration - Configurations associated with request pooling
- cache? CacheConfig - HTTP caching related configurations
- compression Compression(default http:COMPRESSION_AUTO) - Specifies the way of handling compression (
accept-encoding) header
- circuitBreaker? CircuitBreakerConfig - Configurations associated with the behaviour of the Circuit Breaker
- retryConfig? RetryConfig - Configurations associated with retrying
- responseLimits? ResponseLimitConfigs - Configurations associated with inbound response size limits
- secureSocket? ClientSecureSocket - SSL/TLS-related options
- proxy? ProxyConfig - Proxy server related options
- validation boolean(default true) - Enables the inbound payload validation functionality which provided by the constraint package. Enabled by default
openai.chat: CreateChatCompletionRequest
Fields
- messages ChatCompletionRequestMessage[] - A list of messages comprising the conversation so far. Depending on the model you use, different message types (modalities) are supported, like text, images, and audio.
- model string|"o1-preview"|"o1-preview-2024-09-12"|"o1-mini"|"o1-mini-2024-09-12"|"gpt-4o"|"gpt-4o-2024-11-20"|"gpt-4o-2024-08-06"|"gpt-4o-2024-05-13"|"gpt-4o-realtime-preview"|"gpt-4o-realtime-preview-2024-10-01"|"gpt-4o-audio-preview"|"gpt-4o-audio-preview-2024-10-01"|"chatgpt-4o-latest"|"gpt-4o-mini"|"gpt-4o-mini-2024-07-18"|"gpt-4-turbo"|"gpt-4-turbo-2024-04-09"|"gpt-4-0125-preview"|"gpt-4-turbo-preview"|"gpt-4-1106-preview"|"gpt-4-vision-preview"|"gpt-4"|"gpt-4-0314"|"gpt-4-0613"|"gpt-4-32k"|"gpt-4-32k-0314"|"gpt-4-32k-0613"|"gpt-3.5-turbo"|"gpt-3.5-turbo-16k"|"gpt-3.5-turbo-0301"|"gpt-3.5-turbo-0613"|"gpt-3.5-turbo-1106"|"gpt-3.5-turbo-0125"|"gpt-3.5-turbo-16k-0613" - ID of the model to use. See the model endpoint compatibility table for details on which models work with the Chat API.
- store boolean?(default false) - Whether or not to store the output of this chat completion request for use in our model distillation or evals products.
- frequency_penalty decimal?(default 0) - Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model's likelihood to repeat the same line verbatim. See more information about frequency and presence penalties.
- logit_bias? record { int... }? - Modify the likelihood of specified tokens appearing in the completion. Accepts a JSON object that maps tokens (specified by their token ID in the tokenizer) to an associated bias value from -100 to 100. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
- logprobs boolean?(default false) - Whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the
contentofmessage.
- top_logprobs? int? - An integer between 0 and 20 specifying the number of most likely tokens to return at each token position, each with an associated log probability.
logprobsmust be set totrueif this parameter is used.
- max_tokens? int? - The maximum number of tokens that can be generated in the chat completion. This value can be used to control costs for text generated via API.
This value is now deprecated in favor of
max_completion_tokens, and is not compatible with o1 series models.
- max_completion_tokens? int? - An upper bound for the number of tokens that can be generated for a completion, including visible output tokens and reasoning tokens.
- n int?(default 1) - How many chat completion choices to generate for each input message. Note that you will be charged based on the number of generated tokens across all of the choices. Keep
nas1to minimize costs.
- modalities? ChatCompletionModalities? -
- prediction? PredictionContent? - Configuration for a Predicted Output, which can greatly improve response times when large parts of the model response are known ahead of time. This is most common when you are regenerating a file with only minor changes to most of the content.
- audio? CreateChatCompletionRequest_audio? -
- presence_penalty decimal?(default 0) - Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model's likelihood to talk about new topics. See more information about frequency and presence penalties.
- response_format? ResponseFormatText|ResponseFormatJsonObject|ResponseFormatJsonSchema - An object specifying the format that the model must output. Compatible with GPT-4o, GPT-4o mini, GPT-4 Turbo and all GPT-3.5 Turbo models newer than
gpt-3.5-turbo-1106. Setting to{ "type": "json_schema", "json_schema": {...} }enables Structured Outputs which ensures the model will match your supplied JSON schema. Learn more in the Structured Outputs guide. Setting to{ "type": "json_object" }enables JSON mode, which ensures the message the model generates is valid JSON. Important: when using JSON mode, you must also instruct the model to produce JSON yourself via a system or user message. Without this, the model may generate an unending stream of whitespace until the generation reaches the token limit, resulting in a long-running and seemingly "stuck" request. Also note that the message content may be partially cut off iffinish_reason="length", which indicates the generation exceededmax_tokensor the conversation exceeded the max context length.
- seed? int? - This feature is in Beta.
If specified, our system will make a best effort to sample deterministically, such that repeated requests with the same
seedand parameters should return the same result. Determinism is not guaranteed, and you should refer to thesystem_fingerprintresponse parameter to monitor changes in the backend.
- service_tier "auto"|"default"?(default "auto") - Specifies the latency tier to use for processing the request. This parameter is relevant for customers subscribed to the scale tier service:
- If set to 'auto', and the Project is Scale tier enabled, the system will utilize scale tier credits until they are exhausted.
- If set to 'auto', and the Project is not Scale tier enabled, the request will be processed using the default service tier with a lower uptime SLA and no latency guarentee.
- If set to 'default', the request will be processed using the default service tier with a lower uptime SLA and no latency guarentee.
- When not set, the default behavior is 'auto'.
service_tierutilized.
- 'stream boolean?(default false) - If set, partial message deltas will be sent, like in ChatGPT. Tokens will be sent as data-only server-sent events as they become available, with the stream terminated by a
data: [DONE]message. Example Python code.
- stream_options? ChatCompletionStreamOptions? -
- temperature decimal?(default 1) - What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
We generally recommend altering this or
top_pbut not both.
- top_p decimal?(default 1) - An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
We generally recommend altering this or
temperaturebut not both.
- tools? ChatCompletionTool[] - A list of tools the model may call. Currently, only functions are supported as a tool. Use this to provide a list of functions the model may generate JSON inputs for. A max of 128 functions are supported.
- tool_choice? ChatCompletionToolChoiceOption -
- parallel_tool_calls? ParallelToolCalls -
- user? string - A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. Learn more.
- function_call? "none"|"auto"|ChatCompletionFunctionCallOption - Deprecated in favor of
tool_choice. Controls which (if any) function is called by the model.nonemeans the model will not call a function and instead generates a message.automeans the model can pick between generating a message or calling a function. Specifying a particular function via{"name": "my_function"}forces the model to call that function.noneis the default when no functions are present.autois the default if functions are present.
- functions? ChatCompletionFunctions[] - Deprecated in favor of
tools. A list of functions the model may generate JSON inputs for.
openai.chat: CreateChatCompletionRequest_audio
Parameters for audio output. Required when audio output is requested with
modalities: ["audio"]. Learn more.
Fields
- voice "alloy"|"ash"|"ballad"|"coral"|"echo"|"sage"|"shimmer"|"verse" - The voice the model uses to respond. Supported voices are
ash,ballad,coral,sage, andverse(also supported but not recommended arealloy,echo, andshimmer; these voices are less expressive).
- format "wav"|"mp3"|"flac"|"opus"|"pcm16" - Specifies the output audio format. Must be one of
wav,mp3,flac,opus, orpcm16.
openai.chat: CreateChatCompletionResponse
Represents a chat completion response returned by model, based on the provided input.
Fields
- id string - A unique identifier for the chat completion.
- choices CreateChatCompletionResponse_choices[] - A list of chat completion choices. Can be more than one if
nis greater than 1.
- created int - The Unix timestamp (in seconds) of when the chat completion was created.
- model string - The model used for the chat completion.
- service_tier? "scale"|"default"? - The service tier used for processing the request. This field is only included if the
service_tierparameter is specified in the request.
- system_fingerprint? string? - This fingerprint represents the backend configuration that the model runs with.
Can be used in conjunction with the
seedrequest parameter to understand when backend changes have been made that might impact determinism.
- 'object "chat.completion" - The object type, which is always
chat.completion.
- usage? CompletionUsage - Usage statistics for the completion request.
openai.chat: CreateChatCompletionResponse_choices
Fields
- finish_reason "stop"|"length"|"tool_calls"|"content_filter"|"function_call" - The reason the model stopped generating tokens. This will be
stopif the model hit a natural stop point or a provided stop sequence,lengthif the maximum number of tokens specified in the request was reached,content_filterif content was omitted due to a flag from our content filters,tool_callsif the model called a tool, orfunction_call(deprecated) if the model called a function.
- index int - The index of the choice in the list of choices.
- message ChatCompletionResponseMessage -
- logprobs CreateChatCompletionResponse_logprobs? -
openai.chat: CreateChatCompletionResponse_logprobs
Log probability information for the choice.
Fields
- content ChatCompletionTokenLogprob[]? - A list of message content tokens with log probability information.
- refusal ChatCompletionTokenLogprob[]? - A list of message refusal tokens with log probability information.
openai.chat: FunctionObject
Fields
- description? string - A description of what the function does, used by the model to choose when and how to call the function.
- name string - The name of the function to be called. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64.
- parameters? FunctionParameters -
- strict boolean?(default false) - Whether to enable strict schema adherence when generating the function call. If set to true, the model will follow the exact schema defined in the
parametersfield. Only a subset of JSON Schema is supported whenstrictistrue. Learn more about Structured Outputs in the function calling guide.
openai.chat: FunctionParameters
The parameters the functions accepts, described as a JSON Schema object. See the guide for examples, and the JSON Schema reference for documentation about the format.
Omitting parameters defines a function with an empty parameter list.
openai.chat: PredictionContent
Static predicted output content, such as the content of a text file that is being regenerated.
Fields
- 'type "content" - The type of the predicted content you want to provide. This type is
currently always
content.
- content string|ChatCompletionRequestMessageContentPartText[] - The content that should be matched when generating a model response. If generated tokens would match this content, the entire model response can be returned much more quickly.
openai.chat: ProxyConfig
Proxy server configurations to be used with the HTTP client endpoint.
Fields
- host string(default "") - Host name of the proxy server
- port int(default 0) - Proxy server port
- userName string(default "") - Proxy server username
- password string(default "") - Proxy server password
openai.chat: ResponseFormatJsonObject
Fields
- 'type "json_object" - The type of response format being defined:
json_object
openai.chat: ResponseFormatJsonSchema
Fields
- 'type "json_schema" - The type of response format being defined:
json_schema
- json_schema ResponseFormatJsonSchema_json_schema -
openai.chat: ResponseFormatJsonSchema_json_schema
Fields
- description? string - A description of what the response format is for, used by the model to determine how to respond in the format.
- name string - The name of the response format. Must be a-z, A-Z, 0-9, or contain underscores and dashes, with a maximum length of 64.
- schema? ResponseFormatJsonSchemaSchema -
- strict boolean?(default false) - Whether to enable strict schema adherence when generating the output. If set to true, the model will always follow the exact schema defined in the
schemafield. Only a subset of JSON Schema is supported whenstrictistrue. To learn more, read the Structured Outputs guide.
openai.chat: ResponseFormatJsonSchemaSchema
The schema for the response format, described as a JSON Schema object.
openai.chat: ResponseFormatText
Fields
- 'type "text" - The type of response format being defined:
text
Union types
openai.chat: ChatCompletionRequestMessage
ChatCompletionRequestMessage
openai.chat: ChatCompletionRequestUserMessageContentPart
ChatCompletionRequestUserMessageContentPart
openai.chat: ChatCompletionToolChoiceOption
ChatCompletionToolChoiceOption
Controls which (if any) tool is called by the model.
none means the model will not call any tool and instead generates a message.
auto means the model can pick between generating a message or calling one or more tools.
required means the model must call one or more tools.
Specifying a particular tool via {"type": "function", "function": {"name": "my_function"}} forces the model to call that tool.
none is the default when no tools are present. auto is the default if tools are present.
openai.chat: ChatCompletionRequestAssistantMessageContentPart
ChatCompletionRequestAssistantMessageContentPart
Array types
openai.chat: ChatCompletionMessageToolCalls
ChatCompletionMessageToolCalls
The tool calls generated by the model, such as function calls.
openai.chat: ChatCompletionModalities
ChatCompletionModalities
Output types that you would like the model to generate for this request. Most models are capable of generating text, which is the default:
["text"]
The gpt-4o-audio-preview model can also be used to generate audio. To
request that this model generate both text and audio responses, you can
use:
["text", "audio"]
Simple name reference types
openai.chat: ChatCompletionRequestSystemMessageContentPart
ChatCompletionRequestSystemMessageContentPart
openai.chat: ChatCompletionRequestToolMessageContentPart
ChatCompletionRequestToolMessageContentPart
Boolean types
openai.chat: ParallelToolCalls
ParallelToolCalls
Whether to enable parallel function calling during tool use.